In principio, c'era l'hashing delle password e tutto era buono. L'uno-direzionale natura del hash fatto sì che, una volta passati attraverso un algoritmo di hashing la password memorizzata poteva essere convalidato da un altro hash password (di solito fornito al momento dell'accesso) e confrontandoli. Tutti erano felici.
Poi è arrivato tali tabelle arcobaleno fastidiosi. Improvvisamente, enormi collezioni di password e hash possono essere memorizzati in queste tabelle colorate piccoli quindi rispetto agli attuali password hashing (spesso violato dalle banche dati di altre persone) ad una velocità impressionante di nodi così rivelare la versione originale testo. Bugger.
Così abbiamo iniziato a condire le nostre password con il sale. L'aggiunta di bytes casuali per la password prima che fosse introdotto l'imprevedibilità hash che è stata la kryptonite per l'uso del tavolo arcobaleno di pre-calcolate hash. Improvvisamente, quelle belle tabelle di hash per le password di struttura comune divenne inutile, perché l'hash salata era del tutto insolita.
Ma ora c'è una nuova minaccia per tutti, che ha trasformato le tabelle hash salata - la legge di Moore . Della legge Naturalmente Moore in sé non è una novità, è solo che sia stata effettuata sulla potenza di elaborazione del computer al punto che ciò che una volta era un bar computazionalmente molto alta - il manuale di calcolo di un gran numero di hash - sta rapidamente diventando uno molto bassa bar. Peggio di tutto, è di lasciare i nostri password hashing vulnerabili al punto che molte pratiche esistenti apportano salatura e hashing quasi inutile.
Un riassunto veloce hashing
Facciamo un rapido passo indietro prima di parlare di cosa c'è di sbagliato con gli algoritmi di hashing di oggi. Il problema che lo stoccaggio di crittografia delle password sta cercando di affrontare è quello di limitare il danno potenziale di divulgazione non intenzionale di password in memoria. Ora, naturalmente, tutte le buone pratiche di sicurezza a monte come l'attenuazione contro le vulnerabilità SQL injection e proteggere i backup sono ancora validi,si tratta di cosa accade quando le cose vanno davvero male.
Ci è stato ricordato di questo giorno solo l'altro quando WHMCS è stato violato e migliaia di dati dell'account sono trapelati . In questo caso sembra che alcuni di ingegneria sociale di base è stato utilizzato per aggirare la sicurezza del padrone di casa permettendo così l'accesso al database degli account utente. E 'stata una storia simile con LinkedIn appena un po' più tardi, quando 6 milioni di password sono stati esposti attraverso la (ancora) i mezzi sconosciuti o riservate. Divulgazione delle password in deposito accade. Lotti.
Quindi questo è davvero il punto di hash - una volta che si appartengono, nella misura in cui WHMCS e LinkedIn sono stati, sicuro di memorizzazione delle password di crittografia è l'unica cosa salvare le credenziali del cliente. E ricordate, una grande percentuale di queste credenziali verranno riutilizzati su altri servizi di stoccaggio in modo sicuro è di proteggere molto di più che solo il sito che è stato violato.
Il trucco è quello di garantire lo sforzo di "rompere" l'hashing supera il valore che gli autori otterranno in questo modo. Niente di tutto questo è di essere "unhackable", si tratta di fare la difficoltà di farlo, non vale la pena . In questo caso, quando dico "break" o "crack", sto parlando di ri-elaborazione hash anziché trovare punti deboli degli stessi algoritmi. Sto letteralmente parlando di prendere una stringa di testo normale, hashing poi confrontare con una password già in deposito. Se corrispondono, poi ho appena scoperto la password di testo normale.
Un rapido recap password di pratiche
Per prima cosa - ci succhiano a scegliere password. Grande tempo. Quando ho analizzato una delle violazioni Sony l'anno scorso, ho trovato un certo numero di pratiche piuttosto scadenti:
- 93% aveva tra i 6 e 10 caratteri
- 45% è stato composto interamente da caratteri minuscoli
- 36% sono stati trovati in un dizionario password comune
- 67% sono stati riutilizzati dalla stessa persona su un servizio totalmente indipendenti (Gawker)
- Solo l'1% di essi conteneva un carattere non alfanumerico
Ciò significa che nella scala delle password potenziali - che utilizza tutti i caratteri disponibili e renderle il più lungo e unico come desiderato - le password sono conformi ai modelli molto, molto prevedibili. In realtà hai solo bisogno di prendere una gamma molto limitata (ad esempio 6-8 carattere minuscolo) e si sta andando a coprire un numero significativo di password.Oppure, in alternativa, si prende un elenco di password comuni in un "dizionario" password e si sta andando ad avere un risultato simile. Più su quello a breve.
Il provider di appartenenza ASP.NET
Sono stato un sostenitore del provider di appartenenze ASP.NET per una serie di motivi:
- E 'estremamente facile da costruire registrazione, accesso e servizi di gestione degli account in cima.
- I modelli di Visual Studio per siti Web ASP.NET hanno un sacco di questa funzionalità già costruito pollici
- L'accesso alla base dati del database e viene generata automaticamente risparmiando un sacco di manuali «standard» codifica.
- Le impostazioni predefinite di archiviazione ad un meccanismo di password "sicura" salata hash SHA1.
I primi tre punti sono ancora molto rilevante, l'ultimo, non tanto. Diamo uno sguardo sotto le coperte.
In primo luogo, guardiamo il sale. Si tratta di una stringa di 16 byte crittograficamente casuali generati dal RNGCryptoServiceProvider poi codificato Base64:
private string GenerateSalt () { byte [] data = new byte [0x10]; nuova RNGCryptoServiceProvider () GetBytes (dei dati);. ritorno Convert . ToBase64String (dati); }
Il sale viene poi spacciato al metodo EncodePassword insieme alla password e il formato vorremmo memorizzare la password in (stiamo solo ipotizzando SHA1 per il momento). Questo metodo è un po 'lunga, ma ho intenzione di includere tutto perché so che alcune persone piace prendere lo distingue:
private string EncodePassword ( stringa pass, int passwordFormat, stringa di sale) { se (passwordFormat == 0) { ritorno passare; } byte [] bytes = Encoding Unicode.GetBytes (pass);. byte [] src = Convert . FromBase64String (sale); byte [] = inArray nulla , se (passwordFormat == 1) { HashAlgorithm hashAlgorithm = questo . GetHashAlgorithm (), se (hashAlgorithm è KeyedHashAlgorithm ) { KeyedHashAlgorithm algorithm2 = ( KeyedHashAlgorithm ) hashAlgorithm; se (algorithm2.Key.Length == src.Length) { algorithm2.Key src =; } else if (algorithm2.Key.Length <src.Length) { byte [] dst = new byte [algorithm2.Key.Length]; Buffer . BlockCopy (src, 0, dst, 0, dst.Length); algorithm2.Key = dst; } else { int num2; byte [] buffer5 = new byte [algorithm2.Key.Length]; per ( int i = 0; i <buffer5.Length; i + = num2) { num2 = Math Min (src.Length, buffer5.Length - i);. Buffer . BlockCopy (src, 0, buffer5, i, num2); } algorithm2.Key = buffer5; } inArray algorithm2.ComputeHash = (byte); } else { byte [] buffer6 = new byte [+ src.Length bytes.Length]; Buffer . BlockCopy (src, 0, buffer6, 0, src.Length); Buffer . BlockCopy (bytes, 0, buffer6 e src.Length, bytes.Length); inArray = hashAlgorithm.ComputeHash (buffer6); } } else { byte [] buffer7 = new byte [+ src.Length bytes.Length]; Buffer . BlockCopy (src, 0, buffer7, 0, src.Length); Buffer . BlockCopy (bytes, 0, buffer7 e src.Length, bytes.Length); inArray = questo . EncryptPassword (buffer7, questo . _LegacyPasswordCompatibilityMode ); } ritorno Conversione ToBase64String (inArray).; }
Si noti che prima che la password viene generato un hash, il sale è Base64 de codificato (linea 8 sopra) in modo che quando si vede il sale nel database è necessario ricordare che non è la stringa che è stato utilizzato nel processo effettivo di salatura. Per esempio, quando vediamo il sale "AB1ZYgDjTR4alp4jYq4XoA ==", questo è il valore codificato dei byte di origine. La password di hash è di per sé anche Base64 codificati prima di essere memorizzate nel livello dei dati.
Cracking alla velocità di GPU
Si tratta di un AMD Radeon HD 7970 :

Si tratta di un high-end consumer scheda grafica vendite al dettaglio per circa $ 500 in Australia. Ho comprato uno l'altro giorno, in parte per aumentare le schermate del mio vecchio consentite e in parte per capire di più su ciò che accade in hash di cracking. Qui è dove hashcat entra in gioco Vedete, utilizzando hashcat di sfruttare la potenza della GPU nel 7970 si può generare fino a 4.7393 miliardi di hash al secondo . Proprio così, miliardicome in b per "fast sanguinosa".
Algoritmi di hashing differenti eseguono a velocità diverse e questo è un concetto chiave per questo articolo. Il marchio 4.7b è per MD5 che è considerato antiquato. Le varianti SHA sono generalmente preferito (come è il caso il provider di appartenenza) e la velocità per SHA1 scende fino a "solo" hash 2.2b al secondo.
Che cosa significa è semplicemente questo: se hai il sale e si ha l'hash della password, un veloce GPU sta per permette di generare hash di nuovi utilizzando il sale e confrontarle con la password esistente hash ad un ritmo estremamente veloce. Ripetere questa operazione più volte e alla fine ti corrispondere al hash appena generato contro la stored uno così "cracking" la password. Diamo un andare a questo.
Creare un ambiente di test
Torniamo a questa analisi la password Sony ho menzionato in precedenza. Ci sono stati quasi 40.000 password in chiaro in tale violazione (a seconda di come si de-dupe it) e quello che sto per fare è usare quelle per rigenerare "assicurare" i conti con il provider di appartenenza ASP.NET. Sto facendo questo perché voglio usare password realistici in questa demo in modo da avere una idea reale di come funziona tutto.
Saltai in Visual Studio 2010 e ha creato un nuovo MVC 3 app in esecuzione. NET 4 e poi sceneggiato la creazione di account in base alle password Sony. Come funziona?Semplicemente enumerazione attraverso la logica di creazione account:
foreach ( var la password in password) { MembershipCreateStatus createStatus; Membership CreateUser (. "user" + i, / nome / utente password.Password, / / Password "foo@bar.com" , / / Email nulla , / question / password nulla , / / Password risposta vera , / / è stato approvato nulla , / / fornitore chiave out createStatus); / / Stato i + +; }Una volta che questo viene eseguito, ecco quello che finisce con il database:

Se si sta utilizzando il provider di appartenenze per qualsiasi dei vostri progetti, avrete una struttura che sembra proprio come questo nel vostro database. Il nome della tabella possono essere diversi, come i modelli più recenti in Visual Studio 2012 implementare il modello di web provider per l'adesione , ma è esattamente la struttura del database stesso. E 'questo meccanismo di archiviazione che stiamo ora andando a rompere.
L'ipotesi che andremo a fare è che questo database è stato violato. Naturalmente abbiamo aderito a tutte le indicazioni buon sviluppo di applicazioni in fonti come la OWASP Top 10 , ma alla fine il male ha superato bene e gli hash sono là fuori nel selvaggio.
Per iniziare screpolature quei hash abbiamo bisogno di scaricarli in un formato che hashcat capisce. Il modo in cui offerte di hashcat con gli hash è che definisce un certo tipo hash e richiede un elenco di hash di una struttura corrispondente. In questo caso, andremo ad utilizzare il modello EPiServer .
Cosa c'è EPiServer? EPiServer è una "gestione dei contenuti, community e social media, del commercio e della comunicazione" del prodotto, ma ciò che è importante per noi è che si siede sulla parte superiore del provider di appartenenza ASP.NET (che probabilmente sarebbe stato un titolo più adatto per hashcat per l'uso).
Il formato abbiamo bisogno di usare coinvolge quattro delimitato "colonne" di una stella:
- La firma hash - "EPiServer $ $"
- La versione - è tutto "0", che implica SHA1
- La codifica base64 sale
- L'hash codificato base64
Questo è facile da eseguire il dump di SQL Server in modo da finire con un file di testo chiamato "MembershipAccounts.hash" che assomiglia a questo:
$episerver$*0*Z5+ghPUN6L8bVjdZFLlknQ==*dGOIcZDFNETO8cyY4i0BGcOD+mg=
$episerver$*0*detWsWTuzxI21nzefT6tNQ==*FbVX28Yaw5tPGj2sZUS38Cm5obk=
$episerver$*0*yZmUqUTKjod0TjBgS6y74w==*dWsNk9FEB8uAcPGhuzgKw+EdYF0=
$episerver$*0*heFEX9ej5vTa9G7X5QB8Fw==*TR2abu7N2xxqXxleggRXIBuqhr8=
$episerver$*0*xffmFD4ynyLnMkdzvbvuLw==*+1aODh+RowjblZupczhVuZzkmvk=
$episerver$*0*e++8ztWilfow0nli7Tk2PA==*acTusUU8a11uSaKbr/EKo7NNFNk=
$episerver$*0*qjAbSa51wjAxxBIVYu98Rg==*YIFas6OtzjQ3aKoOelIBjA9BvNM=
...
$episerver$*0*detWsWTuzxI21nzefT6tNQ==*FbVX28Yaw5tPGj2sZUS38Cm5obk=
$episerver$*0*yZmUqUTKjod0TjBgS6y74w==*dWsNk9FEB8uAcPGhuzgKw+EdYF0=
$episerver$*0*heFEX9ej5vTa9G7X5QB8Fw==*TR2abu7N2xxqXxleggRXIBuqhr8=
$episerver$*0*xffmFD4ynyLnMkdzvbvuLw==*+1aODh+RowjblZupczhVuZzkmvk=
$episerver$*0*e++8ztWilfow0nli7Tk2PA==*acTusUU8a11uSaKbr/EKo7NNFNk=
$episerver$*0*qjAbSa51wjAxxBIVYu98Rg==*YIFas6OtzjQ3aKoOelIBjA9BvNM=
...
Quindi questo è gli hash pronto ad andare, adesso dobbiamo solo capire come stiamo andando a rompere loro.
Dizionario basata su password di cracking
Quando parliamo di "cracking" hash, stiamo davvero parlando solo di rigenerare in massa e ci sono diversi modi in cui possiamo farlo. Il modo più semplice e laborioso è quello di lavorare solo attraverso un set di caratteri e la portata, ad esempio per le lettere minuscole solo tra 6 e 9 caratteri. Questo sarebbe in realtà coprono l'82% delle password, ma Sony si tradurrebbe in 104,459,430,739,968 possibilità (che sarebbe 104 miliardi ), così anche a velocità di GPU che stai guardando ora per la password , come ognuno ha bisogno di essere attaccato in modo univoco a causa del sale. Significherebbe fare questo:
SHA1 (sale + "aaaaaa")
SHA1 (sale + "aaaaab")
SHA1 (sale + "aaaaac")
...
SHA1 (sale + "aaaaab")
SHA1 (sale + "aaaaac")
...
Per tutto il tragitto fino a 9 caratteri e tutto il percorso attraverso l'alfabeto minuscolo. Ma questo non è come la gente la creazione di password - è troppo casuale. Naturalmente casuale è come la gente dovrebbe creare password - ma non lo fanno. La realtà è che la maggior parte delle persone siano conformi a modelli di password molto più prevedibili, in realtà sono così prevedibili che abbiamo password "dizionari".
Questo non è il vostro o la vostra Oxford Webster, piuttosto un dizionario password è una raccolta di password comunemente utilizzate spesso raccolti da violazioni precedenti.Naturalmente questo non è esaustivo - ma è abbastanza .
"Basta" è un concetto molto importante quando si parla di craccare le password, ma non è necessariamente esaustivo circa rompendo ogni uno di loro e risolvere in testo semplice, si tratta di avere successo sufficiente a giustificare l'obiettivo . Ovviamente l'obiettivo sarà diverso tra i malfattori, ma la questione per noi come sviluppatori e proprietari app è "quanto è abbastanza?" Voglio dire quanto è sufficiente a lasciarci in una posizione molto appiccicoso (ancor più che il fatto i nostri dati è stato violato in primo luogo)? Un quarto di loro? La metà di loro? Forse solo uno di loro?
Tornando ai dizionari, l'obiettivo quando craccare le password è quello di utilizzare un dizionario che è abbastanza vasta da dare un buon raccolto, ma non così esteso che sia troppo dispendioso di tempo. Ricordate, quando si parla di hash salate quindi ogni singolo record ha bisogno di farsi valutare con il dizionario in modo che quando abbiamo grandi quantità di password può diventare un esercizio molto tempo.
Il dizionario che ho scelto per questo esercizio è uno da InsidePro appropriatamente chiamato hashkiller (in realtà, lo chiamano hashkiller.com, ma non sembra essere qualche cosa su quella URL). Si tratta di un file di 241MB che contiene 23,685,601 'parole' in formato testo, solo uno per riga. Perché le virgolette intorno a "parole"? Perché contiene cose come "! $ @ @ @ "(Spazi ci sono come si trova),"!! 888888 "e"!!! # @ # # # # # ". Esso contiene inoltre 5.144 varianti del "tette" parola (sì - ho controllato) in modo, come potete vedere, non è a corto di varietà.
Screpolatura
Il processo di cracking è molto semplice: si dispone di due ingressi, che sono l'elenco dei sali con hash e poi c'è il dizionario password. Questi sono passati al comando hashcat con un parametro per indicare il tipo di hash abbiamo a che fare con il quale è il formato EPiServer ("-m 141"). Ecco come appare il comando:
oclHashcat plus64.exe-m-141 MembershipAccounts.hash hashkiller.com.dic
Voglio cercare di dare un senso di quanto velocemente questo processo esegue così ho compilato all'inizio e alla fine in un breve video narrato (è sintetizzato più avanti, se si desidera saltare through):
Impressionante? Abbastanza, ma anche un po 'paura. Diamo uno sguardo più da vicino il riassunto dopo tutto quello che è stato eseguito:
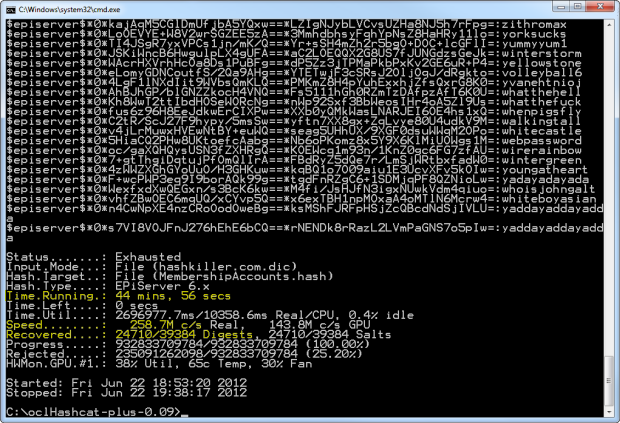
Quello che una volta considerato "sicuro" - che è salito hash SHA -. È stato appena cancellato Infatti nel tempo necessario per guardare un paio di episodi di Family Guy, abbiamo incrinato 24,710 hash o 63% della dimensione totale del campione. Il restante 37% semplicemente non erano nel dizionario password ma un dizionario più grande e forse seduto attraverso il Signore degli Anelli e il tasso di successo sarebbe molto più alto. Il punto è chesi tratta di una quantità insignificante di tempo da trascorrere in rottura di una parte significativa degli hash.
Cosa c'è di più, ci sono le password in là che molti considerano essere "forte". Che ne dite di "volleyball6" - 11 caratteri di due tipi diversi. Più in alto la lista è stata "zaq1 @ WSX" - 8 caratteri di superiore, inferiore numerica e simboli, sicuramente abbastanza per passare maggior parte delle politiche di sicurezza ma anche quando hash memorizzato come un "sicuro" salata, assolutamente inutile.
Tutte queste password cracking sono stati salvati in un file chiamato "hashcat.pot". Ecco cosa c'è dentro:
$episerver$*0*v4jLrMuwxHVEwNtBY+euWQ==*seag5UHhUX/9XGF0dsuWWqM2OPo=:whitecastle
$episerver$*0*5HiaCQ2PHw8UKtoefcAabg==*Nb6oPKomz8x5Y9X6KlMiUOWgs1M=:webpassword
$episerver$*0*oc/gaXQHQysUSN3fZXHRgQ==*KOEWcq1m93n/1KnZ0gc6FG7zfAU=:wirerainbow
$episerver$*0*7+gtThgiDqtujPfOmQlIrA==*FBdRyZ5dQe7r/LmSjWRtbxfadW0=:wintergreen
$episerver$*0*4zWWZXGhGYoUuO/H3GHKuw==*kqBQ1o7O09aiu1E3UcvXFv5kOIw=:youngatheart
$episerver$*0*F+wcPWP3eq9I9borAQk99g==*tgdFnRZgC6+1SDMjqPF8QZNioLw=:yadayadayada
$episerver$*0*WexfxdXwQEGxn/s3BcK6kw==*M4fi/JsHJfN3igxNUwkVdm4qiuo=:whoisjohngalt
$episerver$*0*vhfZBwOEC6mqUQ/xCYvp5Q==*x6exTBH1npMOxaA4oMTlN6Mcrw4=:whiteboyasian
$episerver$*0*n4CwNpXE4nzCRoOodOweBg==*ksMShFJRFpHSjZcQBcdNdSjIVLU=:yaddayaddayadda
$episerver$*0*s7VI8VOJFnJ276hEhE6bCQ==*rNENDk8rRazL2LVmPaGNS7o5pIw=:yaddayaddayadda
$episerver$*0*5HiaCQ2PHw8UKtoefcAabg==*Nb6oPKomz8x5Y9X6KlMiUOWgs1M=:webpassword
$episerver$*0*oc/gaXQHQysUSN3fZXHRgQ==*KOEWcq1m93n/1KnZ0gc6FG7zfAU=:wirerainbow
$episerver$*0*7+gtThgiDqtujPfOmQlIrA==*FBdRyZ5dQe7r/LmSjWRtbxfadW0=:wintergreen
$episerver$*0*4zWWZXGhGYoUuO/H3GHKuw==*kqBQ1o7O09aiu1E3UcvXFv5kOIw=:youngatheart
$episerver$*0*F+wcPWP3eq9I9borAQk99g==*tgdFnRZgC6+1SDMjqPF8QZNioLw=:yadayadayada
$episerver$*0*WexfxdXwQEGxn/s3BcK6kw==*M4fi/JsHJfN3igxNUwkVdm4qiuo=:whoisjohngalt
$episerver$*0*vhfZBwOEC6mqUQ/xCYvp5Q==*x6exTBH1npMOxaA4oMTlN6Mcrw4=:whiteboyasian
$episerver$*0*n4CwNpXE4nzCRoOodOweBg==*ksMShFJRFpHSjZcQBcdNdSjIVLU=:yaddayaddayadda
$episerver$*0*s7VI8VOJFnJ276hEhE6bCQ==*rNENDk8rRazL2LVmPaGNS7o5pIw=:yaddayaddayadda
Questo è più o meno solo la lista di hash di origine con la password in formato testo aggiunto alla fine. Nella maggior parte dei casi in cui i conti sono stati violati, gli hash a vista e sali siederà accanto al nome utente e indirizzi di posta elettronica in modo armato di informazioni di cui sopra è semplice unire tutto torna insieme.
Un'ultima cosa prima di passare, avete notato la velocità di cracking 258.7M era "solo" al secondo? Che fine ha fatto il throughput teorico di un paio di miliardi di hash SHA1 al secondo? Il problema è che il throughput superiore può essere raggiunto solo con "mutazioni" di valori dizionario delle password o di lavoro attraverso la possibilità di password differenti direttamente all'interno della GPU. In altre parole, se si lascia che la GPU assume un valore dizionario poi trasformarla in una serie di possibilità diverse può lavorare molto più velocemente. La GPU non può essere alimentati password abbastanza veloce per raggiungere lo stesso livello di throughput in modo efficace con una lista delle password è collo di bottiglia.
Si può effettivamente osservare la GPU solo lavorando a circa metà della sua potenzialità; ecco ciò che il MSI Afterburner Hardware Monitor aveva da dire sul 7970 solo lavorando direttamente attraverso il dizionario a sinistra rispetto applicando mutazioni al dizionario a destra:


Vedere la GPU% di utilizzo nei grafici secondo? Quando il 7970 si avvia si avvicina a quella massima utilizzazione e le rampe dei ventilatori fino tutto inizia a suonare un po 'jet-motore-a-max-spinta. Ma alla fine, mentre il tasso di hashing dizionario diretti potranno essere inferiori, la precisione è significativamente più elevato e il tempo per produrre risultati significativi è più favorevole.
Come possiamo risolvere questo problema?
Ecco, questo è la cattiva notizia - le hash SHA salate sono quasi inutili contro la maggior parte delle password degli utenti in genere creano . Il provider di appartenenza ASP.NET offre ora poco più di una sottile patina di sicurezza delle password in deposito. E non credo che si possa risolvere il problema andando a SHA256 come attuata in System.Web.Providers , è quasi meglio di SHA1 in termini di tasso al quale si crea hash.Abbiamo bisogno di una migliore trappola per topi.
Ecco il problema:

Gli hash dei membri del provider erano spaccati perché è troppo dannatamente veloce per rigenerarli. Questo potrebbe sembrare un sacrilegio in un mondo in cui noi sviluppatori fanno di tutto per guadagnarsi da ogni skerrick ultima delle prestazioni in ogni punto possibile, ma hash veloci stanno uccidendo la nostra sicurezza.
Ma veniamo un po 'di contesto qui - abbiamo davvero bisogno di essere in grado di generare 4,7 miliardi di hash di password al secondo? E 'come prendere l'intera popolazione Facebook di oltre 900 milioni di euro e in sequenza hashing ogni singola password 5 volte al secondo .Ed è su hardware consumer. No, non abbiamo bisogno di arrivare ovunque, anche vicino a quello.
Il problema è che algoritmi come MD5 e SHA sono stati progettati per dimostrare l'integrità dei dati ad alta velocità computazionale piuttosto che fornire un meccanismo di stoccaggio password; crittografiche funzioni di hash non sono di password funzioni hash . Anche se fossero "sicuri" per la memorizzazione delle password quando sono concepiti, MD5 risale a 20 anni con la legge di Moore ora abbiamo processori che sono ora otto mila volte più veloce .
Ci sono diversi approcci per infondendo nuova vita a vecchi algoritmi; chiave che si estende, per esempio, dove un algoritmo che è troppo veloce è "rallentato", ripetendolo più e più volte, forse migliaia di volte. Ma la guida in giro per artisti del calibro di MD5 e SHA è chiara e OWASP riassume concisamente :
Algoritmi di hashing generali (ad esempio, MD5, SHA-1/256/512) non sono raccomandati per la memorizzazione delle password. Invece un algoritmo specificamente progettato per lo scopo deve essere utilizzato.
Ciò di cui abbiamo bisogno è un algoritmo di hashing che è stato progettato dalla terra in su con velocità in mente, non veloce velocità, ma bassa velocità.
Edit: io ero un po 'vago qui e molte persone mi hanno chiamato su di esso. Il concetto di aumentare lo sforzo richiesto per eseguire la funzione hash è uno che è spesso implementata da stiramento chiave e in effetti questo è il modus operandi di PBKDF2. In realtà PBKDF2 può quindi essere applicato a un algoritmo SHA così come a rigor di termini, SHA è ancora in uso, solo che non come lo conosciamo nella sua forma singola iterazione. Diventa allora una questione di quante iterazioni sono sufficienti, che parlo un po 'più in basso.
Ci sono algoritmi di hashing numerose volte a fare questo: bcrypt, PBKDF2 solo per citarne un paio. Il problema è che il sostegno per questi differisce tra i quadri e il loro livello di integrazione profonda con caratteristiche come il provider di appartenenza ASP.NET è spesso inesistente o un cittadino di seconda classe ai loro cugini più veloci. Ma la cosa come questi algoritmi è che sono adattativi :
Nel tempo può essere fatto più lento così rimane resistente agli specifici forza bruta attacchi ricerca contro la hash e il sale.
Chiaramente la capacità di aumentare il carico di lavoro è importante se non vogliamo essere catturati dalla legge di Moore di nuovo in un prossimo futuro. Tutti abbiamo bisogno è un modo per integrare questo nel nostro lavoro esistente.
"Fissare" la password hashing ASP.NET
Per fortuna ci sono un certo numero di soluzioni disponibili per implementare gli algoritmi di hashing più forti in ASP.NET. Per cominciare, c'è l'attuazione Zetetic di bcrypt e PBKDF2 per il provider di appartenenze . Il bello di questo approccio è che si può cadere direttamente nella vostra applicazione esistente da NuGet :

Zetetic fa uso di bcrypt.net modo che tu possa sempre e solo andare a prendere quella direttamente se non desidera implementare il provider intera appartenenza. Purtroppo c'è un grave inconveniente con l'attuazione di Zetetic - richiede l'installazione e la modifica GAC machine.config . Questo è un peccato in quanto esclude ambienti ospitati fuori molti come la devo usare per ASafaWeb con AppHarbor . Sono in grado di distribuire quasi tutto mi piace in app , ma non c'è modo posso arrivare ovunque nei pressi del GAC o machine.config in un ambiente condiviso.
Poi ci sono implementazioni come CryptSharp da Chris McKee , che rendono estremamente semplice da implementare e bcrypt PBKDF2 insieme ad altri, come SCrypt e Blowfish. Non c'è diretta integrazione provider di appartenenze, ma poi c'è anche alcuna dipendenza GAC o machine.config.
Qualche discussione si accende su quale degli algoritmi più lente sono il giusto approccio. Ad esempio, quali sono approvate dal NIST - e non ancora importa? C'è tutto un mondo di vantaggi e svantaggi, alti e bassi, ma l'unica cosa che è universalmente convenuto è che MD5 e SHA sono ora semplicemente non abbastanza sicuro per la memorizzazione delle password.
L'impatto di hash lente sulla velocità (e sovraccarico della CPU)
Rallentare hashing potrebbe essere solo bene per la sicurezza, ma quali altre conseguenze negative potrebbero avere? Bene per uno, il processo di accesso sarà più lento. Ma cerchiamo di essere pragmatici su questo - se un esercizio che dovrebbe accadere non più di una volta per ogni sessione all'altra estremità di tutto ciò che latenza di rete e tempo di rendering del browser aggiunge, per esempio, 200 ms per il processo, che importa? La maggior parte sostengono "no" - è una quantità impercettibile di tempo di incremento trascurabile al tempo attuale di attesa dell'utente ed è inserito in un processo di frequente.
Ma per quanto riguarda il sovraccarico sul server stesso? Voglio dire sono gli algoritmi di hashing più lenti sufficientemente computazionalmente costoso avere un impatto negativo delle risorse al punto in cui sta andando a costare soldi per maggiori risorse? Alcuni dicono "sì" , è una preoccupazione e che con un numero sufficiente hashing simultanei in corso che sta per avere sul serio impatto negativo. In questo esempio, 100 thread simultanei consumato 95% delle risorse della CPU per 38 secondi in modo evidente che c'è un problema.
Mi piace avere questo problema! Immaginate la scala è necessario raggiungere per avere 100 persone discrete allo stesso tempo tentando di hash di una password via di accesso, la registrazione o modificare la password con una certa frequenza - che un problema gloriosa di avere! Per raggiungere una scala in cui hashing lento ha quel tipo di impatto - o anche solo il 10% di questi numeri - si sta parlando di un app seriamente di grandi dimensioni. Si consideri un singolo accesso per ogni sessione, l'uso della funzione "ricordati di me" (a torto oa ragione), la frequenza d'uso poi accostare che con un processo che, anche quando volutamente lento è probabilmente da qualche parte nel campo di 100ms. Ma, naturalmente, con un adattamento algoritmo di hash come bcrypt non deve essere 100ms, può essere la metà, o raddoppiare o qualsiasi altra cosa che si decide è il giusto equilibrio tra velocità e rischio per la sicurezza sul hardware si sta eseguendo oggi . Sia chiaro che questa è sicuramente una cosa da considerare, non è solo qualcosa che molti di noi ha bisogno di preoccuparsi.
Parte del problema è che quando applichiamo hash ai fini della memorizzazione delle password in modo che stiamo facendo sulla CPU - che è lento - ma poi, quando qualcuno tenta di crack che stanno facendo così sul G PU - che è veloce . Suscitare una maggiore carico di lavoro può essere applicato in modo uniforme in entrambe le unità di elaborazione, ma fa male da quella prevista per l'hashing legittimi molto più di quanto fa male quello frequentemente usato per scopi malvagi. Semplicemente non è giusto!
Una scuola di pensiero è quello di hashing leva GPU sul server in modo efficace per livellare il campo di gioco. Se la CPU è veramente 150 volte più lento di password hash allora non avrebbe senso per spostare questo processo alla GPU poi basta cricchetto il carico di lavoro fino ad un limite accettabile? Questa potrebbe essere la soluzione perfetta anche se ovviamente è necessario avere l'hardware a disposizione (e non stai andando a trovare GPU veloce già nella maggior parte dei server) più il codice responsabile per l'hashing ha bisogno di indirizzare la GPU che certamente non è la posizione di default per la maggior parte basati su server implementazioni di hashing.
Ma ha avuto un po 'mi ha incuriosito, ciò che realmente è l'impatto di impiegare hashing lente in un ambiente vivo? E c'è molta differenza di velocità tra le varianti SHA e bcrypt MD5, o anche per quella materia? Così ho costruito una demo per contribuire a dare un certo contesto e metterlo qui: https://asafaweb.com/HashSpeed
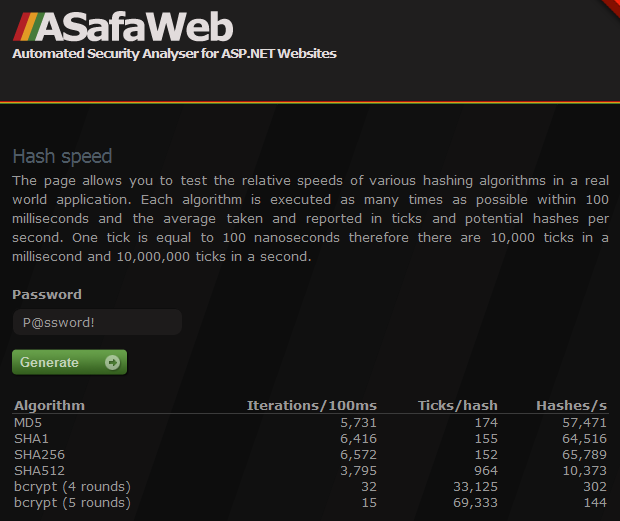
Questo non è un sito ad alto volume, in realtà è un volume molto basso, ma viene eseguito in cloud pubblico AppHarbor e quindi condivide le risorse con ogni sorta di altre applicazioni.Come tale, la velocità è incoerente in più è dipendente dalla classe Stopwatch , che può essere imprevedibile (per inciso, i risultati sono stati molto più stabile nel mio ambiente locale e anche significativamente più veloce).
Ci sono alcune lezioni da portare via da questo:
- Relativamente parlando, la velocità di SHA1 e SHA256 è vicino a ciascuno e sia anche in prossimità MD5 - circa una variazione del 15% al massimo.
- SHA512 può sembrare un po 'più lenta, ma è ancora modo troppo veloce per le password hashing (hashcat sostiene 73 milioni al secondo nel 7970 GPU).
- Vi è una grande differenza tra le varianti MD5 e SHA rispetto a bcrypt anche con un piccolo numero di giri (default bcrypt.net a 10 che 32 volte più lento con 5 colpi).
Quando ci si può sintonizzare l'overhead di elaborazione dell'algoritmo di hash non c'è davvero molto di un argomento per fare in termini di esso aggiunta di overhead inaccettabile per l'ambiente. Troppo lento? Accelerarlo. Non è come si sta andando per ottenere tutta la strada fino alla velocità di base del CSA in ogni caso, non ci dovrebbe mai essere il caso di sub-millisecondo l'hashing delle password come dimostrato nell'esempio di cui sopra.
Dimenticate il generico orientamento della password
Una cosa che ho sempre trovato un po 'divertente - soprattutto alla luce dell'esercizio di fessurazione precedenza - è una guida lungo le linee di "Ci vorrà un numero X di giorni / settimane / mesi per craccare una password particolare. Permettetemi di dimostrare con la password "00455455mb17" utilizzando il sito Passfault :

Beh, questo dovresti farlo! Il problema è che abbiamo appena rotto in 45 minuti. In realtà, più precisamente, abbiamo rotto questo uno e gli altri 24.709 come pure, ma lascia i capelli non dividere. Scelta delle password (e più specificamente, di cracking), non è soggetto alle mere regole di entropia, no, l'unicità è assolutamente essenziale per proteggere loro e viceversa la prevedibilità è una parte fondamentale della loro rottura.
Infine, alcuni consigli pratici
Che cosa possiamo concludere da questo esercizio? Permettetemi di riassumere:
SHA salato è vicino inutile: Mi dispiace di essere portatore di cattive nuove (in realtà, uno dei tanti portatori), ma, la velocità e la facilità con cui prezzo salato SHA può essere violataper la maggior parte delle password è troppo semplice.
Utilizzare un algoritmo adattivo hashing: Avete numerose opzioni, alcune delle quali sono stati discussi qui. Scegli uno - con la cura appropriata.
Trovare un equilibrio tra velocità e le prestazioni: più lenti algoritmi di aumentare l'overhead di calcolo in modo da adattare il fattore lavoro per soddisfare sia la capacità delle infrastrutture e il volume del pubblico.
Ma dopo tutto questo parlare di GPU e gli algoritmi hash e la velocità ce n'è uno davvero, una soluzione molto semplice che vi porterà 60 secondi per implementare e rendere le password nei pressi di uncrackable . E 'questo:
<add name="AspNetSqlMembershipProvider" minRequiredPasswordLength="30" minRequiredNonalphanumericCharacters="5" />
Questo è tutto - aumentare i requisiti di lunghezza e complessità, al punto che è altamente probabile che le password scelti sarà unica, per non parlare di fuori della gamma di modelli di default la maggior parte di cracking. Naturalmente, purtroppo, nessuno sano di mente sta andando a chiedere questo grado di complessità perché la maggior parte degli utenti non dispongono di un mezzo per tenere traccia delle password immemorabili. E 'un peccato, però, perché questo è più o meno tutti i nostri problemi di cracking risolto proprio lì.
Ma lasciatemi concludere questo con la seguente citazione dalla prefazione di Bruce Schneier Crittografia applicata :
Ci sono due tipi di crittografia in questo mondo: di crittografia che non si fermerà la vostra sorellina di leggere i vostri file e crittografia, che si fermerà principali governi di leggere i file.
Questa in effetti sembra essere il caso e, purtroppo, SHA è ora saldamente in prima categoria.
Nessun commento:
Posta un commento