Ho sentito parlare di questo ragazzo, entrato in una banca federale con un telefono portatile, consegnato il telefono al cassiere, il tizio all'altro capo del telefono ha detto: "Abbiamo avuto la bambina di questo ragazzo, e se non lo danno tutti i vostri soldi, stiamo andando uccidere 'er. "
Ha funzionato?
F ** kin 'A ha funzionato, che è quello che sto talkin' about! Knucklehead entra in una banca con un telefono, non una pistola, non un fucile, ma af ** kin 'telefono, pulisce il posto fuori, e loro non sollevare af ** kin' dito.
Hanno male la bambina?
Non lo so. Probabilmente mai C'era una bambina - il punto della storia non è la bambina. Il punto della storia è che rapinato la banca con un telefono.
Questo è fuori di scena di Pulp Fiction di apertura e chiarezza, è fittizia. Tranne quando non è:
Avviso di estorsione
Brian Krebs riferito questo a pochi mesi fa , ed è quanto di più sfacciata come ci si aspetterebbe criminali online per ottenere; ci danno i soldi o ti rovinare la vostra roba. E 'il racket di protezione mafia dell'era digitale più casuale con meno possibilità di essere scoperti e non come molte collane d'oro (presumo). Quello bitcoin è di circa $ 400 dollari americani oggi in modo sufficiente per un ritorno poco ordinata ma non abbastanza che si fa per un riscatto irraggiungibile per la maggior parte delle piccole imprese.
La cosa preoccupante è, però, questo è solo parte di una tendenza più ampia che sta disegnando i criminali online nel mondo molto lucrativo di estorsione e stiamo vedendo molti nuovi precedenti in tutti i tipi di diverse aree del mondo online. Lasciate che vi mostri quello che voglio dire.
Distruggere un business via web
Diciamo che avete un desiderio per un piatto di carne di leone di un giorno (mi avete sentito) in modo da fare una ricerca su Google e trovare il ristorante perfetto - ma è chiudere il fine settimana. Bugger. Così si va da qualche altra parte, come fanno tutti gli altri cacciatori di cibi esotici alla ricerca del re della giungla con un lato di patatine fritte. Questo è stato il destino della corona serba negli Stati Uniti ha incontrato all'inizio di quest'anno (questo è un collegamento archivio web, non assicurarsi che il suono sia acceso fino a godere l'esperienza completa):
Il serbo Crown
Vedete, qualche anima intraprendente aveva deciso di prendere l'iniziativa di creare una voce di Google Places per il comune e travisato le loro ore di funzionamento:
Si è scoperto che Google Places, vasta directory business del gigante della ricerca, è stato errate il serbo della Corona ore. Chiunque Googling Serbian Crown, o collegarlo a Google Maps, è stato detto erroneamente che il ristorante era chiuso durante il fine settimana
Il punto di tutto questo è che quando si tratta di lettere di estorsione, gli aggressori possono effettivamente essere molto efficace nello svolgimento dei loro minacce. Essi possono distruggere le imprese a tal punto che un Bitcoin o due per mantenere in vita improvvisamente non sembra un cattivo affare e questo è enormemente preoccupante. Ma l'ondata di estorsione che abbiamo visto quest'anno va ben oltre le semplici minacce di danneggiare l'attività della vittima, sempre l'attaccante possiede già il bersaglio e ora stanno parlando riscatto.
Spionaggio industriale e di riscatto
In realtà ho avuto questo post del blog in progetto per un po ', aggiungendo pezzi di come si sono verificati nuovi eventi. Il catalizzatore per il completamento è stato questo :
Sony Hacked By #GOP
Questo è stato presumibilmente "su tutti i computer in tutto Sony Pictures nazionale" oggi. Il file zip riferimento contiene un paio di centinaia mega di file di testo con elenchi di file che sembrano legittime. Se si prende questo al valore nominale (e dato che hanno dimostrato di avere il controllo di un numero di account Sony Pictures Twitter che è il presupposto sicuro per fare), che è una quantità enorme di dati sensibili sono seduti su. Ecco solo un frammento di quello che ho trovato questa mattina:
Elenco di file Presunta dalla Sony mod
Non è chiaro che cosa #GOP ha chiesto di Sony, ma ciò che è chiaro è che potenzialmente hanno in mano un mucchio di dati molto sensibili lì. Al momento della scrittura, la loro scadenza era in corso una mezza giornata fa e non c'era ancora alcun rilascio di massa di dati al pubblico in modo chiaro che era una minaccia a vuoto, giusto? O forse Sony paga up? Fa Qualcuno paga up? A quanto pare sì.
Una storia di successo estorsione: Nokia
All'inizio di quest'anno c'è stato un rapporto che nel 2007, Nokia ha pagato un estorsore "diversi milioni di euro" per alcune chiavi di crittografia . Holy crap fa pagare di business! A volte.
Il problema in un caso come questo è che il pagamento del estorsione fatto buon senso finanziario di Nokia. Aveva qualcuno ha iniziato a sfruttare quelle chiavi per firmare i pacchetti con i quali potrebbero poi essere installata sui dispositivi sotto l'identità di Nokia, che avrebbero potuto prendere un enorme successo sulla fiducia dei consumatori nel momento in cui stavano appena iniziando a perdere quote di mercato serio.
Pensate estorsori stanno prendendo di mira persone giuridiche? Pensare ancora, i consumatori di tutti i giorni sono sempre colpiti troppo.
La meccanica del "trucco" iCloud e come i dispositivi iOS sono trattenuti in ostaggio
E 'non solo i grandi di essere colpiti con riscatti, ogni giorno i consumatori sono sempre il ping da attaccanti troppo. Nel maggio ho scritto su questo :
iPhone hacked by Oleg Pliss
Questo particolare ha colpito Aussies ignari, per motivi che non erano evidenti, al momento, ma poi si è rivelato essere a causa di pagine di phishing che inevitabilmente avuto un debole per il targeting quelli di noi down under. Mentre questo è stato spesso segnalato come il malware, non c'era "ware" ad esso, piuttosto si trattava di un caso dell'attaccante semplicemente utilizzando la funzione "Trova il mio iPhone" per bloccare in remoto il dispositivo e quando non PIN schermata di blocco esisteva e impostare una di loro. Avete ottenuto il PIN, una volta pagato il denaro. E 'stato ingegnosamente semplice.
Naturalmente i consumatori sono stati colpiti con riscatti prima, CryptoLocker è un perfetto esempio di questo. Si ottiene di malware tramite uno dei mezzi abituali, tutte le tue cose vengono criptati e poi l'attaccante chiede soldi per rilasciare la chiave privata per voi. Questo è un altro che è stato molto efficace qui con un caso particolarmente elevato profilo di uno studio medico di essere colpito un paio di anni fa .
Un flusso apparentemente infinito di taglie
Riscatti sembrano essere davvero colpire le fasce come di ritardo. Al di là di tutti i casi di cui sopra, ci sono incidenti come Dominos in Francia, torna nel mese di giugno con gli hacker esigenti € 30.000 e la speculazione diffusa sia su di esso essendo stato pagato e respinto. Probabilmente solo Dominos e gli attaccanti sanno per certo.
Il mese dopo che era la Banca centrale europea sempre violato e presumibilmente minacciata da un ricattatore.
Un mese più tardi di nuovo e telefoni Android accusano le persone di gradire i loro animali domestici solo un po 'troppo esigenti e denaro per non essere segnalato per l'FBI che sono evidentemente interessati a queste cose.
Proprio la scorsa settimana è stata la città di Detroit ottenere proprietà con attaccanti che vogliono un paio di migliaia di Bitcoin per i loro problemi . Detroit di tutti i posti! Non sono forse quelli in cattive acque finanziarie ?!
Ransoms aumenteranno perché fanno buon senso
Pensateci: non dovete venire faccia a faccia con chiunque come nelle racket delle estorsioni di vecchio, è possibile eseguire l'intero concerto dal vostro ufficio / camera da letto / prigione, ci sono cose più e più connesso con sempre più vulnerabilità, siamo sia personalmente che professionalmente più che mai dipendenti servizi online e meglio di tutti, abbiamo un facile accesso alla valuta crypto per quando vittima pay up!
Beh in realtà, anche meglio che (per gli attaccanti, almeno), perché fa buon senso finanziario per le vittime a pagare, perché in molti casi gli aggressori hanno fatto un lavoro dannatamente buono. Questo non è un avallo l'etica del tutto, piuttosto un'osservazione che in molti di questi casi, che hanno effettivamente lasciato la vittima con poca scelta: pagare o essere seriamente disturbato. Stanno facendo il ritorno sugli investimenti troppo attraente per dire "no", e questo è un trend estremamente preoccupante.
E 'anche meglio di camminare in banca con un telefono, in questi giorni è sufficiente inviare una e-mail anonima.
lunedì 15 dicembre 2014
giovedì 11 dicembre 2014
Applied Azure: "Non ho avuto pwned" Infografica di come orchestra servizi cloud di Microsoft
Ricordate i bei vecchi tempi in cui un sito web usato per essere niente di più di un gruppo di file su un server web e un database di back-end? La vita era semplice, facile da gestire e gloriosamente inefficiente. Aspetta - che cosa? Proprio così, tutti abbiamo avuto è stato un martello e di conseguenza trattati ogni sfida come il chiodo proverbiale che era così abbiamo risolto allo stesso modo con gli stessi strumenti più e più volte. Non importava che un sito web ASP.NET su IIS era del tutto inadeguato a eventi di pianificazione, questo è tutto quello che avevamo e abbiamo fatto funzionare. Allo stesso modo con SQL Server; era enorme eccessivo per molti requisiti di persistenza di dati semplici, ma ci aveva speso i soldi per le licenze e abbiamo avuto una dose malsana di avversione alla perdita accoppiato con una carenza di alternative valide.
Questo era il vecchio mondo e se si sta ancora lavorando in questo modo, si sta perdendo tempo grande. Probabilmente stai spendendo troppo denaro e rendendo così la vita troppo duro con se stesso. Ma siamo anche essere realistici - ci sono un mucchio di bit nel "nuovo mondo" e questo significa un sacco di cose da imparare e avvolgere la testa intorno. L'ampiezza e la profondità dei servizi che costituiscono ciò che noi conosciamo come Microsoft Azure sono, senza dubbio, impressionante. Quando si guarda a infografica come questo si inizia ad avere un senso di quanto sia vasta la piattaforma è. È inoltre possibile ottenere un po 'sopraffatto con quanti servizi ci sono e forse confuso su come si dovrebbe legarli insieme.
Ho pensato prendo suddetta infografica e trasformarlo in quello che ho io stato pwned? (HIBP) è oggi. Oh - e parlando di oggi - è esattamente un anno da quando ho lanciato HIBP! Uno dei motivi principali che ho costruito il servizio in primo luogo è stato quello di mettere le mani avanti con tutti i servizi Azure avrete letto su di seguito. Non avevo idea di quanto sia popolare il servizio sarebbe stato quando ho deciso di costruirlo e come ben si sarebbe dimostrare le proposte di valore nube che vengono con scala massiccia fluttuante, grandi volumi di memorizzazione dei dati e una serie di funzionalità che è distribuito attraverso una gamma di servizi cloud discreti.
Ecco l'infografica, fare clic through per una risoluzione ad alta PNG o andare vettore con PDF e leggere dopo che per maggiori dettagli su come è tutto messo insieme.
Questo era il vecchio mondo e se si sta ancora lavorando in questo modo, si sta perdendo tempo grande. Probabilmente stai spendendo troppo denaro e rendendo così la vita troppo duro con se stesso. Ma siamo anche essere realistici - ci sono un mucchio di bit nel "nuovo mondo" e questo significa un sacco di cose da imparare e avvolgere la testa intorno. L'ampiezza e la profondità dei servizi che costituiscono ciò che noi conosciamo come Microsoft Azure sono, senza dubbio, impressionante. Quando si guarda a infografica come questo si inizia ad avere un senso di quanto sia vasta la piattaforma è. È inoltre possibile ottenere un po 'sopraffatto con quanti servizi ci sono e forse confuso su come si dovrebbe legarli insieme.
Ho pensato prendo suddetta infografica e trasformarlo in quello che ho io stato pwned? (HIBP) è oggi. Oh - e parlando di oggi - è esattamente un anno da quando ho lanciato HIBP! Uno dei motivi principali che ho costruito il servizio in primo luogo è stato quello di mettere le mani avanti con tutti i servizi Azure avrete letto su di seguito. Non avevo idea di quanto sia popolare il servizio sarebbe stato quando ho deciso di costruirlo e come ben si sarebbe dimostrare le proposte di valore nube che vengono con scala massiccia fluttuante, grandi volumi di memorizzazione dei dati e una serie di funzionalità che è distribuito attraverso una gamma di servizi cloud discreti.
Ecco l'infografica, fare clic through per una risoluzione ad alta PNG o andare vettore con PDF e leggere dopo che per maggiori dettagli su come è tutto messo insieme.
mercoledì 3 dicembre 2014
NoSQL for .NET: RavenDB 3.0 prende il volo
Tra uno stuolo di nuove funzionalità in questo aggiornamento per il motore di database open source NoSQL alternativo per .NET è un nuovo sistema di storage engine e il file.
By Michael Domingo2014/12/02
Con sede in Israele Hibernating Rhinos ha messo gli ultimi ritocchi al suo open source motore di database NoSQL RavenDB 3.0.3528 for .NET e reso disponibile al pubblico. La nuova versione è stata annunciata dallo sviluppatore Oren Eini, che blog su di esso attraverso il suo blog personaggio online Ayende @ Rahein.
Una lunga lista di funzionalità nuove e aggiornate sono elencati qui . Importanti anche il supporto per il motore di archiviazione di Windows estensibile o di nuova creazione del motore di storage Voron di Hibernating Rhino.
La società comprende anche RavenFS, un file system creato internamente che supporta i backup completi e incrementali, replica e alta disponibilità.
Esportazioni completi e incrementali
Vari metodi di replica.
Transformer nesting: Richiamare il comando TransformWith nelle funzioni di proiezione di trasformazioni complesse nido.
Java API
E 'disponibile attraverso Nuget così come il sito web dell'azienda .
By Michael Domingo2014/12/02
Con sede in Israele Hibernating Rhinos ha messo gli ultimi ritocchi al suo open source motore di database NoSQL RavenDB 3.0.3528 for .NET e reso disponibile al pubblico. La nuova versione è stata annunciata dallo sviluppatore Oren Eini, che blog su di esso attraverso il suo blog personaggio online Ayende @ Rahein.
Una lunga lista di funzionalità nuove e aggiornate sono elencati qui . Importanti anche il supporto per il motore di archiviazione di Windows estensibile o di nuova creazione del motore di storage Voron di Hibernating Rhino.
La società comprende anche RavenFS, un file system creato internamente che supporta i backup completi e incrementali, replica e alta disponibilità.
Esportazioni completi e incrementali
Vari metodi di replica.
Transformer nesting: Richiamare il comando TransformWith nelle funzioni di proiezione di trasformazioni complesse nido.
Java API
E 'disponibile attraverso Nuget così come il sito web dell'azienda .
lunedì 24 novembre 2014
"Non ho avuto pwned?" - Ora con RSS!
Come caratteristica rilasci andare, questo non è esattamente un assassino, ma con mia grande sorpresa è stato uno che è stato richiesto con una certa frequenza. Si scopre che la gente voleva davvero essere in grado di tenere il passo di nuove violazioni e paste in sono stato pwned? (HIBP) via RSS. Non solo che una domanda perfettamente ragionevole, ma è stato anche un solo click per arrivare in cima così qui è!
Ci sono due feed RSS sia legato in da vari luoghi del sito anche in navigazione. Per la vostra convenienza RSS'ing, sono entrambi disponibili come collegamenti diretti qui:
Ultimi 20 violazioni
Ultimi 50 paste
Ho scelto questi numeri perché paste appaiono molto spesso - a volte decine al giorno - mentre le violazioni essendo un processo altamente manuale significa che faccio forse solo un paio al mese in media. Entrambi i feed hanno le loro attrazioni, violazioni, perché è sempre una grave volume di dati da un evento verificato e paste, perché se siete come me, io sono un pò curioso di vedere il tipo di dati che è continuamente oggetto di dumping su Pastebin.
Si può inoltre notare che i feed sono serviti via Feedburner. I lettori abituali ricorderanno che provo e ottimizzare HIBP al grado n'th per ottimizzare realmente le risorse che ho a mia disposizione e mantenere il costo basso. Utilizzando Feedburner come proxy per i feed sottostanti, ho un servizio che colpisce HIBP e poi "n" di voi ragazzi che colpiscono Feedburner. Che mantiene il carico fuori la mia fine e significa anche che Google paga per la larghezza di banda.
Se avete suggerimenti per uno dei feed, come altre informazioni che ci piacerebbe vedere nel titolo o nel corpo, non me lo faccia sapere. Buon divertimento!
mercoledì 19 novembre 2014
Entity Framework 6.1 in Beta
La versione 6.1 contiene alcune correzioni ad alta priorità che devono essere testati in natura prima che sia RTM'd; nel frattempo, la prossima versione di Entity Framework potrebbe essere la versione 7 o qualcosa d'altro.
By Michael Domingo2014/11/18
Una nuova versione di Entity Framework avrebbe dovuto essere rapidamente rilasciato giusto in questo periodo, ma a pochi blog da Rowan Miller di Microsoft indica che un po 'di misura ed il rivestimento deve essere fatto prima di versione 6.1 di RTM.
"Originariamente avevamo intenzione di andare dritto al RTM da Beta 1. Tuttavia, abbiamo finito per prendere una serie di importanti correzioni di bug dopo Beta 1, spediti e abbiamo deciso che il tasso di abbandono della base di codice garantito un altro pre-release prima di RTM," scrivere Miller. Il rilascio è ora previsto per i primi di dicembre, ma ha detto che il piano "potrebbe cambiare se abbiamo ulteriori bug ad alta priorità segnalati su Beta 2."
Le correzioni di bug importanti Miller cita sono in questo link CodePlex , e comprendono un miscuglio di problemi di prestazioni e correzioni di codifica generali.
Nel frattempo, Miller bloggato prima il mese scorso circa il dilemma di denominazione di fronte la squadra con la prossima versione di Entity Framework. "Ci sono stati in realtà tre opzioni che abbiamo discusso in termini di denominazione / marchio per EF7," blog Miller, con l'essere opzioni:. Una versione 7 , b. un sottoinsieme di EF, c. chiamare qualcosa di nuovo con una versione 1.0.
Il dibattito dipende dal fatto che le modifiche a EF sono un incrementale salto di caratteristiche o più di natura evolutiva per garantire la ridenominazione del prodotto. Per carillon, leggere il blog e aggiungere il tuo commento a questa notizia o alla fine del blog qui .
By Michael Domingo2014/11/18
Una nuova versione di Entity Framework avrebbe dovuto essere rapidamente rilasciato giusto in questo periodo, ma a pochi blog da Rowan Miller di Microsoft indica che un po 'di misura ed il rivestimento deve essere fatto prima di versione 6.1 di RTM.
"Originariamente avevamo intenzione di andare dritto al RTM da Beta 1. Tuttavia, abbiamo finito per prendere una serie di importanti correzioni di bug dopo Beta 1, spediti e abbiamo deciso che il tasso di abbandono della base di codice garantito un altro pre-release prima di RTM," scrivere Miller. Il rilascio è ora previsto per i primi di dicembre, ma ha detto che il piano "potrebbe cambiare se abbiamo ulteriori bug ad alta priorità segnalati su Beta 2."
Le correzioni di bug importanti Miller cita sono in questo link CodePlex , e comprendono un miscuglio di problemi di prestazioni e correzioni di codifica generali.
Nel frattempo, Miller bloggato prima il mese scorso circa il dilemma di denominazione di fronte la squadra con la prossima versione di Entity Framework. "Ci sono stati in realtà tre opzioni che abbiamo discusso in termini di denominazione / marchio per EF7," blog Miller, con l'essere opzioni:. Una versione 7 , b. un sottoinsieme di EF, c. chiamare qualcosa di nuovo con una versione 1.0.
Il dibattito dipende dal fatto che le modifiche a EF sono un incrementale salto di caratteristiche o più di natura evolutiva per garantire la ridenominazione del prodotto. Per carillon, leggere il blog e aggiungere il tuo commento a questa notizia o alla fine del blog qui .
giovedì 6 novembre 2014
Miglior consiglio. Mai: Cambia la tua predefinito di Visual Studio Development
Durante l'installazione di Visual Studio, hai scelto un gruppo di impostazioni di default, guidati principalmente da quale lingua si intende utilizzare (C #, Visual Basic, ecc).
Le probabilità sono che non avrai mai bisogno di cambiare le impostazioni ... ma succede. Se, ad esempio, le modifiche azienda da Visual Basic a C #, troverete che tutti i modelli di progetto C # sono sepolti sotto altri tipi di progetto.
Questi sono i passi per modificare le impostazioni:
- Dal menu Strumenti di Visual Studio, selezionare Impostazioni di importazione e di esportazione per aprire l'Importazione e Impostazioni di esportazione guidata.
- Nel primo pannello della procedura guidata, selezionare l'opzione Importa selezionato le impostazioni di ambiente. Fare clic sul pulsante Avanti.
- Selezionare No, l'opzione impostazioni basta importare e fare clic sul pulsante Avanti.
- Nella pagina Scegliere un insieme di impostazioni alla pagina della procedura guidata Importa, selezionare le impostazioni desiderate. Fare clic sul pulsante Avanti.
- Nella pagina finale della procedura guidata, fare clic sul pulsante Fine, il tasto OK su tutte le finestre di dialogo di avviso, e il pulsante Chiudi nella pagina finale della procedura guidata.
E 'facile come quello.
lunedì 3 novembre 2014
Get Mantello. Vai scuro. VPN'ing fuori dal Great Firewall of China
Andiamo attraverso solo alcuni dei modi per consegnare i vostri dati preziosi oltre a persone che vogliono arrivare da qualche parte tra voi e qualsiasi servizio che vuoi parlare con all'altra estremità.
È possibile ottenere pineappled e certo che è stato uno dei miei preferiti per dimostrare perché è solo così dannatamente facile (è anche un pò freddo, se sono onesti).
Il router si connette tramite può essere pwned e il suo DNS cambiato per contribuire a pagare per prostitute brasiliane (sì, avete letto bene).
Il governo tunisino può semplicemente sifone backup di tutti i pacchetti che passano attraverso i fornitori di servizi Internet sotto il loro controllo. Ok, forse non sei in Tunisia, ma penso che siamo tutti un po 'diffidenti nei confronti del governo americano ultimamente anche ...
E così via e così via. Ho visto una grande storia oggi i rischi di wifi pubblico che mette la minaccia di un uomo in attacco centrale (d'ora in poi un attacco MITM) in prospettiva. Come utente iOS, quando ho letto cose come la Cina Massive iCloud Hack , ho un po 'preoccupato. Come utente iOS un viaggio in Cina, ho una VPN ed è lì che entra in gioco Mantello.
Ci sono molti servizio VPN consumatore orientato e mi è stato detto che molti di loro sono eccellenti, che sono sicuro che sono. Ho deciso di dare Mantello un andare in parte perché il loro sito web ha reso molto semplice da capire, in parte perché l'account Twitter in realtà allungò la mano e prese contatto quando ne ho parlato (pro tip: questo è importante per un sacco di persone) e anche in parte perché ha un intro libero e buon piano dei prezzi. E 'stato solo dopo che ho iniziato ad usarlo che ho trovato alcuni altri trucchetti come bene. Si tratta di una semplice applicazione morto e sembra che questo:
Il Mantello app
Questo è molto, molto semplice ed è quello che veramente mi ha eccitato circa Mantello, non molto di più che il piano si è in e alcune impostazioni di base. Andiamo attraverso di loro.
Reti di fiducia
Mantello ha questo concetto di "rete di fiducia", vale a dire quelli che non ti senti avete bisogno di un servizio di VPN. Tenete a mente ciò che fa e non vuol dire però; I "fiducia" la mia rete domestica, ma una volta che il traffico esce dalla porta sul filo di rame, è gioco su. Al contrario, quando sei in VPN è game quando i pacchetti colpito il nodo di uscita presso il provider VPN. Ancora un rischio, solo diverso. Le mie reti di fiducia simile a questa:
Le mie reti di fiducia personali
Si noti come le reti cellulari sono attendibili per impostazione predefinita. Si noti inoltre che questo non significa che si può sempre fidare reti cellulari (hi Iran!), Ma di solito non presentano gli stessi rischi come la rete wifi cafè locale a caso, in particolare quelli con crittografia a zero su di loro.
In ogni caso, l'idea che attraverso la definizione di una whitelist di reti di fiducia si può avere Mantello auto-abilitazione quando ci si connette a una rete non attendibile. Questo è estremamente fredda in quanto consente di avvicinarsi hotspot wireless gratuiti con sconsiderato abbandono. Ok, forse non troppo avventato, è necessaria una connessione prima che il VPN calci e c'è sempre quel piccolo spazio dove il traffico può attraversare una rete in chiaro, ma certamente ti dà la possibilità di navigare attraverso le reti estere con una sicurezza che non sarebbe altrimenti.
Quando ci si connette a una rete che non è sulla lista bianca del mantello, vedrete il collegamento VPN nelle impostazioni:
VPN di collegamento ...
A volte si tratta di pochi secondi, altre volte ... non succede mai. La Cina, in particolare, è noto per bloccare le VPN (si scopre che sono un po 'troppo efficace per i gusti del governo a volte) e ho trovato ad essere molto instabile un sacco di tempo . Poi di nuovo, ho trovato il mio servizio VPN aziendale sul mio portatile per essere instabile e il wifi hotel per essere generalmente traballante in modo da non lasciare che gettano una dispersione su Mantello. Nei test in precedenza, ho trovato Mantello roccia solida per tutto il giorno su reti wireless stabili, quindi sono abbastanza sicuro in cui la colpa per l'instabilità si trova.
Una volta connesso, si arriva alle frecce di serie VPN iOS 'accanto all'indicatore di connessione di rete:
VPN viene mostrato accanto all'indicatore di rete wireless
È possibile confermare il collegamento è garantito da un salto indietro verso l'applicazione Mantello. Questo è stato il mio primo test, quando ho colpito l'aeroporto di Sydney:
Collegato a Qantas-Lounge
Questo è tutto - ora tutto tra il dispositivo e il provider VPN è criptato.
Velocità
Stai sempre andando a prendere un colpo sulla velocità con una VPN, è necessario farlo. Non è solo il processo di crittografia, ma ora piuttosto che andare dal proprio fornitore di servizi per l'indirizzo di destinazione tramite il percorso più efficiente possibile, si sta andando dal fornitore di servizi a un exit node VPN per l'indirizzo di destinazione. Fino a che punto il nodo di uscita è sia dalla origine o di destinazione possono avere un impatto sulla velocità.
Ecco un buon esempio: prima di lasciare Sydney effettuato Mantello sopra la mia connessione 4G ed eseguito un test di velocità. Qui c'è VPN:
40.33Mbps scaricare senza VPN
Ora qui è Mantello in azione:
30.11Mbps download con VPN abilitata
Tenendo presente che i test di velocità possono variare il più delle volte, la latenza è più che triplicato e di conseguenza ho perso un quarto della mia velocità verso il basso e circa il 15% della mia velocità in su. Ma sto ancora ricevendo 30Mbps oltre Mantello che francamente, è davvero buona (almeno per gli standard di rete australiani).
Destinazioni Transporter
L'idea di una destinazione trasportatore è un nodo di uscita per la VPN. Se esco con Sydney allora in primo luogo, si tratta di un breve salto se sono già lì e in secondo luogo, ho un indirizzo IP Sydney accompagna i miei pacchetti in uscita. Modificare la destinazione del teletrasporto e ho un IP diverso in una posizione diversa.
Ecco ciò che è disponibile:
Elenco di tutte le sedi dei trasportatori per Mantello
Una volta che seleziono, per esempio, "Australia", avrò bisogno di aggiornare il dispositivo con un nuovo profilo:
Litst dei profili Mantello vuole installare
Possiamo vedere qui che ci sono ora due impostazioni VPN: l'Australia, quello che ho appena selezionato e "più veloce disponibile", che è la posizione di default. Questo fa solo senso - fanno le cose vanno attraverso ciò che è inevitabilmente il nodo di uscita più vicina o, in alternativa, specificare il proprio che può essere una certa distanza, ma si ottiene in uscita nel vostro paese di scelta.
Fatto questo, ora posso selezionare il profilo VPN Preferirei dalle impostazioni di iOS:
Selezionando il nodo di uscita Sydney
Il che significa che quando controllo il mio indirizzo IP, ci si sente come a casa:
Sydney indirizzo IP mostrato in Mantello
Torna alla posizione più veloce e sono in Giappone, che sarebbe il nodo più vicino al mio collegamento ad internet di Pechino:
Indirizzo IP giapponese illustrato
Commutazione richiede solo pochi secondi, quindi è un esercizio molto, molto basso attrito. Ho finito per lasciare Mantello connessione tramite il percorso più veloce possibile, perché per i miei scopi, la mia preoccupazione principale è mantenere il traffico chiaro di reti di Cina (perché abbiamo fiducia davvero quelli americani che molto di più ...) e ottenere l'accesso ai servizi che voglio, che sono accessibile da praticamente ovunque al di fuori della Cina.
Uscire da una posizione diversa da quella in prossimità può essere enormemente vantaggioso. Ad esempio, la Cina non è vero appassionato di Twitter e Facebook in modo non voglio che il mio traffico in uscita da qualsiasi luogo lì, invece io voglio uscire da qualche parte più amichevole per fluidità social media; Il Giappone non è troppo lontano e non impone le stesse restrizioni.
Sincronizzazione
Io uso sia il mio iPhone e il mio iPad ampiamente e una delle cose che mi piace l'ecosistema Apple (e ad essere onesti, gli altri a fare anche questo), è l'esperienza unificata attraverso i miei dispositivi. I miei segnalibri, le mie foto e la maggior parte dei miei iThings allineano bene attraverso i due. Mantello sincronizza anche le impostazioni e una volta che si effettua un cambiamento, mi spinge a sincronizzare le cose attraverso una notifica nella parte inferiore dello schermo:
"Impostazioni fuori sincrono"
La sincronizzazione, Mantello aperto su iPad e vedo questo:
Sincronizzare le impostazioni su iPad
Toccando la notifica nel piè di pagina scarica i profili aggiornati e ora il tutto non bene tra i dispositivi. In questo caso, ora ho la destinazione del teletrasporto australiano sulla tavoletta.
Piani
Ho detto di essere appassionato di Mantello, perché ho potuto ottenere una demo gratuita, ma francamente il costo è irrilevante in ogni caso. Sono incline a confrontare il costo di cose a buon mercato per il mio budget cappuccino e per una settimana di vacanza in Cina, stiamo guardando a meno di due tazze:
Mantello passa a partire da $ 4,99 per una settimana con dati illimitato
La cosa che amo di questo modello è il "passaggio Settimana". Passo la maggior parte del mio tempo a casa sulle reti di fiducia così non ho bisogno di un abbonamento in corso, ma ho anche regolarmente viaggi in luoghi dove non mi fido della rete o ho bisogno di "essere" in un paese diverso. Essere in grado di sparare solo che per una settimana si inserisce miei movimenti appena perfettamente. Nota c'è anche dati illimitato in quel periodo anche in modo che non sta andando a tagliare fuori di me se decido di, ad esempio, aggiornare iOS su tutti i miei dispositivi durante il viaggio (che per inciso, ho fatto proprio questa settimana).
Quello che una VPN non ti porterà
Permettetemi di soffermarmi brevemente su questo ed è in alcun modo specifico per Mantello. Un servizio di VPN come questo non si ottiene una totale anonimato. Sì, è possibile proteggere i dati tra il dispositivo ei servizi di Mantello, ma ricordati che hai identificato a voi stessi di Mantello (avete bisogno di credenziali) e ora stanno gestendo tutti i vostri pacchetti. Ottengono citato in giudizio per i loro dischi e dovresti lavorare sul presupposto che le abitudini di navigazione sarebbero accessibili alle forze dell'ordine nella loro giurisdizione.
I Suoi dati in uscita la loro VPN ha anche nessuna codifica implicita. Ci sono vari precedenti di dati che vengono intercettati e la pipeline di richiesta (NSA hi!) E si deve lavorare sul presupposto che tutto tra mantello e il servizio di cui si è connessi è un gioco equo.
Come regola generale, io non uso VPN per qualcosa che normalmente non fare dalla mia rete di casa. Non mi assumo l'anonimato - c'è Tor per questo e se siete veramente appassionati, si può navigare in modo anonimo via che attraverso il vostro Mantello VPN.
Get Mantello
Ho scritto questo perché io vado a parlare della sicurezza dei trasporti basta che volevo qualcosa potrei consigliare per esperienza in prima persona in un luogo in cui si ha realmente bisogno. L'unica discussione che ho avuto con i ragazzi mantello era via Twitter quindi questo è come indipendente e come unincentivised come si arriva.
È possibile ottenere pineappled e certo che è stato uno dei miei preferiti per dimostrare perché è solo così dannatamente facile (è anche un pò freddo, se sono onesti).
Il router si connette tramite può essere pwned e il suo DNS cambiato per contribuire a pagare per prostitute brasiliane (sì, avete letto bene).
Il governo tunisino può semplicemente sifone backup di tutti i pacchetti che passano attraverso i fornitori di servizi Internet sotto il loro controllo. Ok, forse non sei in Tunisia, ma penso che siamo tutti un po 'diffidenti nei confronti del governo americano ultimamente anche ...
E così via e così via. Ho visto una grande storia oggi i rischi di wifi pubblico che mette la minaccia di un uomo in attacco centrale (d'ora in poi un attacco MITM) in prospettiva. Come utente iOS, quando ho letto cose come la Cina Massive iCloud Hack , ho un po 'preoccupato. Come utente iOS un viaggio in Cina, ho una VPN ed è lì che entra in gioco Mantello.
Ci sono molti servizio VPN consumatore orientato e mi è stato detto che molti di loro sono eccellenti, che sono sicuro che sono. Ho deciso di dare Mantello un andare in parte perché il loro sito web ha reso molto semplice da capire, in parte perché l'account Twitter in realtà allungò la mano e prese contatto quando ne ho parlato (pro tip: questo è importante per un sacco di persone) e anche in parte perché ha un intro libero e buon piano dei prezzi. E 'stato solo dopo che ho iniziato ad usarlo che ho trovato alcuni altri trucchetti come bene. Si tratta di una semplice applicazione morto e sembra che questo:
Il Mantello app
Questo è molto, molto semplice ed è quello che veramente mi ha eccitato circa Mantello, non molto di più che il piano si è in e alcune impostazioni di base. Andiamo attraverso di loro.
Reti di fiducia
Mantello ha questo concetto di "rete di fiducia", vale a dire quelli che non ti senti avete bisogno di un servizio di VPN. Tenete a mente ciò che fa e non vuol dire però; I "fiducia" la mia rete domestica, ma una volta che il traffico esce dalla porta sul filo di rame, è gioco su. Al contrario, quando sei in VPN è game quando i pacchetti colpito il nodo di uscita presso il provider VPN. Ancora un rischio, solo diverso. Le mie reti di fiducia simile a questa:
Le mie reti di fiducia personali
Si noti come le reti cellulari sono attendibili per impostazione predefinita. Si noti inoltre che questo non significa che si può sempre fidare reti cellulari (hi Iran!), Ma di solito non presentano gli stessi rischi come la rete wifi cafè locale a caso, in particolare quelli con crittografia a zero su di loro.
In ogni caso, l'idea che attraverso la definizione di una whitelist di reti di fiducia si può avere Mantello auto-abilitazione quando ci si connette a una rete non attendibile. Questo è estremamente fredda in quanto consente di avvicinarsi hotspot wireless gratuiti con sconsiderato abbandono. Ok, forse non troppo avventato, è necessaria una connessione prima che il VPN calci e c'è sempre quel piccolo spazio dove il traffico può attraversare una rete in chiaro, ma certamente ti dà la possibilità di navigare attraverso le reti estere con una sicurezza che non sarebbe altrimenti.
Quando ci si connette a una rete che non è sulla lista bianca del mantello, vedrete il collegamento VPN nelle impostazioni:
VPN di collegamento ...
A volte si tratta di pochi secondi, altre volte ... non succede mai. La Cina, in particolare, è noto per bloccare le VPN (si scopre che sono un po 'troppo efficace per i gusti del governo a volte) e ho trovato ad essere molto instabile un sacco di tempo . Poi di nuovo, ho trovato il mio servizio VPN aziendale sul mio portatile per essere instabile e il wifi hotel per essere generalmente traballante in modo da non lasciare che gettano una dispersione su Mantello. Nei test in precedenza, ho trovato Mantello roccia solida per tutto il giorno su reti wireless stabili, quindi sono abbastanza sicuro in cui la colpa per l'instabilità si trova.
Una volta connesso, si arriva alle frecce di serie VPN iOS 'accanto all'indicatore di connessione di rete:
VPN viene mostrato accanto all'indicatore di rete wireless
È possibile confermare il collegamento è garantito da un salto indietro verso l'applicazione Mantello. Questo è stato il mio primo test, quando ho colpito l'aeroporto di Sydney:
Collegato a Qantas-Lounge
Questo è tutto - ora tutto tra il dispositivo e il provider VPN è criptato.
Velocità
Stai sempre andando a prendere un colpo sulla velocità con una VPN, è necessario farlo. Non è solo il processo di crittografia, ma ora piuttosto che andare dal proprio fornitore di servizi per l'indirizzo di destinazione tramite il percorso più efficiente possibile, si sta andando dal fornitore di servizi a un exit node VPN per l'indirizzo di destinazione. Fino a che punto il nodo di uscita è sia dalla origine o di destinazione possono avere un impatto sulla velocità.
Ecco un buon esempio: prima di lasciare Sydney effettuato Mantello sopra la mia connessione 4G ed eseguito un test di velocità. Qui c'è VPN:
40.33Mbps scaricare senza VPN
Ora qui è Mantello in azione:
30.11Mbps download con VPN abilitata
Tenendo presente che i test di velocità possono variare il più delle volte, la latenza è più che triplicato e di conseguenza ho perso un quarto della mia velocità verso il basso e circa il 15% della mia velocità in su. Ma sto ancora ricevendo 30Mbps oltre Mantello che francamente, è davvero buona (almeno per gli standard di rete australiani).
Destinazioni Transporter
L'idea di una destinazione trasportatore è un nodo di uscita per la VPN. Se esco con Sydney allora in primo luogo, si tratta di un breve salto se sono già lì e in secondo luogo, ho un indirizzo IP Sydney accompagna i miei pacchetti in uscita. Modificare la destinazione del teletrasporto e ho un IP diverso in una posizione diversa.
Ecco ciò che è disponibile:
Elenco di tutte le sedi dei trasportatori per Mantello
Una volta che seleziono, per esempio, "Australia", avrò bisogno di aggiornare il dispositivo con un nuovo profilo:
Litst dei profili Mantello vuole installare
Possiamo vedere qui che ci sono ora due impostazioni VPN: l'Australia, quello che ho appena selezionato e "più veloce disponibile", che è la posizione di default. Questo fa solo senso - fanno le cose vanno attraverso ciò che è inevitabilmente il nodo di uscita più vicina o, in alternativa, specificare il proprio che può essere una certa distanza, ma si ottiene in uscita nel vostro paese di scelta.
Fatto questo, ora posso selezionare il profilo VPN Preferirei dalle impostazioni di iOS:
Selezionando il nodo di uscita Sydney
Il che significa che quando controllo il mio indirizzo IP, ci si sente come a casa:
Sydney indirizzo IP mostrato in Mantello
Torna alla posizione più veloce e sono in Giappone, che sarebbe il nodo più vicino al mio collegamento ad internet di Pechino:
Indirizzo IP giapponese illustrato
Commutazione richiede solo pochi secondi, quindi è un esercizio molto, molto basso attrito. Ho finito per lasciare Mantello connessione tramite il percorso più veloce possibile, perché per i miei scopi, la mia preoccupazione principale è mantenere il traffico chiaro di reti di Cina (perché abbiamo fiducia davvero quelli americani che molto di più ...) e ottenere l'accesso ai servizi che voglio, che sono accessibile da praticamente ovunque al di fuori della Cina.
Uscire da una posizione diversa da quella in prossimità può essere enormemente vantaggioso. Ad esempio, la Cina non è vero appassionato di Twitter e Facebook in modo non voglio che il mio traffico in uscita da qualsiasi luogo lì, invece io voglio uscire da qualche parte più amichevole per fluidità social media; Il Giappone non è troppo lontano e non impone le stesse restrizioni.
Sincronizzazione
Io uso sia il mio iPhone e il mio iPad ampiamente e una delle cose che mi piace l'ecosistema Apple (e ad essere onesti, gli altri a fare anche questo), è l'esperienza unificata attraverso i miei dispositivi. I miei segnalibri, le mie foto e la maggior parte dei miei iThings allineano bene attraverso i due. Mantello sincronizza anche le impostazioni e una volta che si effettua un cambiamento, mi spinge a sincronizzare le cose attraverso una notifica nella parte inferiore dello schermo:
"Impostazioni fuori sincrono"
La sincronizzazione, Mantello aperto su iPad e vedo questo:
Sincronizzare le impostazioni su iPad
Toccando la notifica nel piè di pagina scarica i profili aggiornati e ora il tutto non bene tra i dispositivi. In questo caso, ora ho la destinazione del teletrasporto australiano sulla tavoletta.
Piani
Ho detto di essere appassionato di Mantello, perché ho potuto ottenere una demo gratuita, ma francamente il costo è irrilevante in ogni caso. Sono incline a confrontare il costo di cose a buon mercato per il mio budget cappuccino e per una settimana di vacanza in Cina, stiamo guardando a meno di due tazze:
Mantello passa a partire da $ 4,99 per una settimana con dati illimitato
La cosa che amo di questo modello è il "passaggio Settimana". Passo la maggior parte del mio tempo a casa sulle reti di fiducia così non ho bisogno di un abbonamento in corso, ma ho anche regolarmente viaggi in luoghi dove non mi fido della rete o ho bisogno di "essere" in un paese diverso. Essere in grado di sparare solo che per una settimana si inserisce miei movimenti appena perfettamente. Nota c'è anche dati illimitato in quel periodo anche in modo che non sta andando a tagliare fuori di me se decido di, ad esempio, aggiornare iOS su tutti i miei dispositivi durante il viaggio (che per inciso, ho fatto proprio questa settimana).
Quello che una VPN non ti porterà
Permettetemi di soffermarmi brevemente su questo ed è in alcun modo specifico per Mantello. Un servizio di VPN come questo non si ottiene una totale anonimato. Sì, è possibile proteggere i dati tra il dispositivo ei servizi di Mantello, ma ricordati che hai identificato a voi stessi di Mantello (avete bisogno di credenziali) e ora stanno gestendo tutti i vostri pacchetti. Ottengono citato in giudizio per i loro dischi e dovresti lavorare sul presupposto che le abitudini di navigazione sarebbero accessibili alle forze dell'ordine nella loro giurisdizione.
I Suoi dati in uscita la loro VPN ha anche nessuna codifica implicita. Ci sono vari precedenti di dati che vengono intercettati e la pipeline di richiesta (NSA hi!) E si deve lavorare sul presupposto che tutto tra mantello e il servizio di cui si è connessi è un gioco equo.
Come regola generale, io non uso VPN per qualcosa che normalmente non fare dalla mia rete di casa. Non mi assumo l'anonimato - c'è Tor per questo e se siete veramente appassionati, si può navigare in modo anonimo via che attraverso il vostro Mantello VPN.
Get Mantello
Ho scritto questo perché io vado a parlare della sicurezza dei trasporti basta che volevo qualcosa potrei consigliare per esperienza in prima persona in un luogo in cui si ha realmente bisogno. L'unica discussione che ho avuto con i ragazzi mantello era via Twitter quindi questo è come indipendente e come unincentivised come si arriva.
giovedì 23 ottobre 2014
NET Rocks Podcast: La sicurezza dell'internet degli oggetti
Sai come hai sempre voluto una forcella con un processore ARM che potrebbe caricare i dati in modalità wireless su internet? C'mon, si sa che si desidera e ora è possibile ottenere un HAPIfork .
O come circa i tuoi globi di luce? Sì, LIFX totalmente rocce , ma no, non ero così entusiasta all'idea, una volta appresi i vostri vicini potrebbero PWN tuo wifi attraverso di loro .
Questa coraggiosa nuova "Internet degli oggetti" mondo è parti uguali impressionante e spaventoso e sembra che ci sia alcun limite per quanto andremo a collegare le nostre cose. Colleghiamo queste cose a Internet tramite API e, naturalmente, alla fine della giornata, una API non è molto più di un sito web senza un'interfaccia utente. Perché è un sito web che ha ancora vulnerabilità dei siti Web quando mettiamo queste API che stanno dietro le nostre "cose", che sono molto più difficili da monitorare in termini di rischi, a meno che non si sa dove guardare ...
Questo è il motivo per cui ho scritto il corso Pluralsight intitolato Hack Your First API . Ho spiegato perchè questo corso rocce prima quindi non mi soffermerò su di esso qui, ma ho avuto una buona occasione per parlare con il duo impressionante da NET Rocks di nuovo l'altro giorno sulle implicazioni di sicurezza degli oggetti, che cosa significa per collegare tutte le nostre cose e perché si potrebbe non essere più in grado di fidarti del tuo WC.
mercoledì 8 ottobre 2014
Guardando "Non ho avuto pwned?" Notifiche Pastebin in azione
Immagino che questo è ciò che è come quando uno dei tuoi figli ottiene abbastanza vecchio per battere finalmente a qualcosa che hai versato il tuo cuore nel loro insegnamento. Sì, sono orgoglioso ed è impressionante che si è rivelato così bene, ma ero ancora un po 'deluso per ottenere questo l'altro giorno:
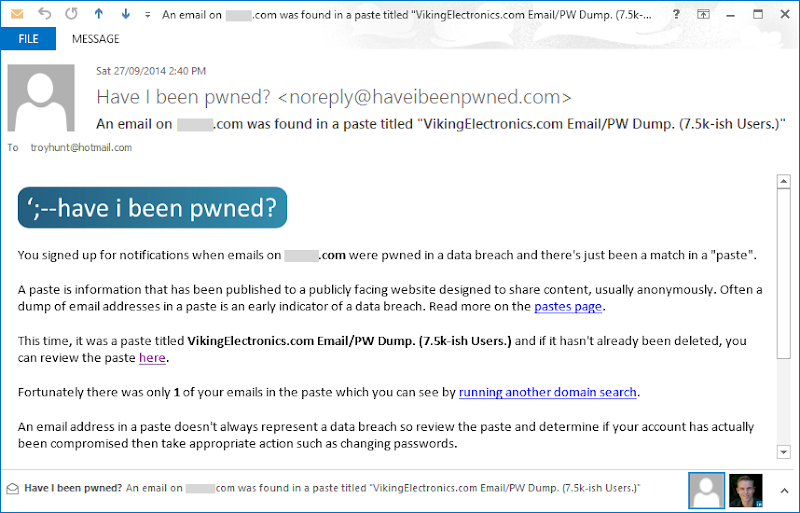
Questo è venuto completamente fuori dal nulla per me che, naturalmente, è esattamente come è pensato per funzionare. Se tutto questo è sconosciuto a voi, questa è la funzione di monitoraggio pasta di "Non ho avuto pwned?" (HIBP), che ho lanciato il mese scorso . Come succede, uno dei domini ho monitor per il lavoro ha avuto un colpo in una pasta dal titolo VikingElectronics.com Email / PW Dump. (7.5K-ish utenti.) - è stato uno dei 7381 messaggi di posta elettronica unici che pasta realmente.
Vedendo questa caratteristica utilizzata per la rabbia è una grande opportunità per vedere come tutto si stringe lungo. Avevo fatto tanto di test, come ho potuto tenerne, ma non c'è niente come vedere risultati concreti dallo strumento facendo organicamente la sua cosa. Ecco cosa è successo nel ciclo di vita dalla pasta stato fatto fino alla ultima volta che tutto ciò che riguarda esso successo:
- 2014/09/27 04: 34: 42.00 (+ 0s): Paste è stata pubblicata
- 2014/09/27 04: 35: 22.00 (+ 40s): Ribaltabile Monitor Tweet fatti
- 2014/09/27 04: 35: 26,84 (+ 45s): Tweet memorizzato nel HIBP DB e inserita in coda di messaggi Azure
- 2014/09/27 04: 35: 30.75 (+ 49s): Messaggio recuperati dalla coda dal ruolo di lavoratore
- 2014/09/27 04: 35: 32,77 (+ 51s): Incolla recuperato da Pastebin
- 2014/09/27 04: 39: 39,81 (+ 298s): Ultimo e-mail salvati in HIBP
- 2014/09/27 04: 40: 10.20 (+ 328S): server SMTP SendGrid ottiene il messaggio
- 2014/09/27 04: 40: 11.08 (329): terre-mail nella mia casella di posta
(In realtà, c'è un punto 9 che arriva un paio di ore dopo tutto questo - la pasta è soppresso.)
Non posso farci niente iniziale 40 secondi di ritardo e sono abbastanza soddisfatto solo essere 11 secondi dopo che è stato fatto che ho recuperato la pasta da Pastebin. E 'un po' di più rispetto ai dati medi che ho osservato nel post di cui sopra ho fatto quando ho lanciato il servizio, ma da qualsiasi misura ragionevole è ancora molto, molto veloce.
Ovviamente il grande ritardo qui è in realtà salvando gli indirizzi email dalla pasta in HIBP. Sono andato avanti e indietro sulla realizzazione di questo un po ', ma in breve il processo di individuazione e l'aggiornamento di una riga nella tabella Azure bagagli non è super-veloce, almeno non senza async'ing che attraverso le righe. Detto questo, stiamo guardando 30 registra un secondo attraverso una abbastanza grande pasta che non è troppo squallido. L'email viene inviata proprio alla fine di salvare tutti i conti a HIBP perché voglio fare in modo che se qualcuno ottiene una mail dicendo "Il tuo account è stato trovato in una pasta", possono andare e cercare immediatamente e realmente trovarlo . Ho anche consolidare la notifica quando vengono inviati messaggi di posta elettronica del dominio (vale a dire "Ci sono stati 3 indirizzi e-mail dal tuo dominio trovati") e quindi ho bisogno di tutti loro elaborare pienamente e salvarli in Tabella bagagli prima di inviare la notifica e-mail.
E 'stato solo poche settimane da quando ho lanciato questo nuovo servizio e stiamo già guardando 1.000 nuove paste da allora che comprende 800.000 conti. Questo è più di un quarto di milione di conti supplementari aggiunti ogni singola settimana. In realtà è abbastanza significativo che tra Mi cominciando a scrivere questo post sul blog in risposta l'avviso sopra e fare clic sul pulsante Pubblica, ho avuto due più di loro. Una delle segnalazioni di fatto incluse account da due domini separati I monitor. Questo è ciò che mi piace molto di questo servizio - si siede proprio lì sullo sfondo ticchettio lontano, a guardare quello che sta succedendo e l'invio di messaggi di posta elettronica, come richiesto.
Le notifiche sono impressionanti. Sono anche liberi e non ci sono in corso 100.000 persone che ottengono quando le violazioni dei dati o paste verificate vengono caricati nel sistema. Ottenere su oltre e impostare le notifiche , perché le probabilità sono voi siete come me - siamo stati sia pwned o quasi certamente sarà pwned e quando ciò accade, io voglio sapere al più presto.
martedì 30 settembre 2014
Any Way the Wind Blows
Con il tasso di turnover per gli sviluppatori di applicazioni di punta di Ventozoom, qualche parte del sistema deve essere maledetto. Dopo che Robert è entrato nel team, e vedere come il suo predecessore gestito dizionari, lui può capire.
Di Mark Bowytz2014/09/29
Poiché atterraggio a Ventozoom sei mesi indietro, Robert ha lavorato su una singola applicazione - un'applicazione NET piuttosto complesso, con una base di codice criptico da abbinare. Dice di essere responsabile di diversi separazioni dei dipendenti, è il tipo di applicazione che ha iniziato la vita come una soluzione mod-sporco e veloce innocente per un piccolo gruppo di clienti che, con l'aiuto di un team di aggressivi ragazzi di vendita, rapidamente cresciuti.
E con il numero di clienti, così è cresciuto richieste di nuove funzionalità.
Aggiungere alla miscela risultante dei requisiti mutevoli e funzionalità di scorrimento, i soliti ingredienti di cui avete bisogno per trasformare un problema in una davvero grande casino strisciato via: mancanza di manodopera, la mancanza di competenza nel manodopera disponibile e, ultimo ma non meno importante, la mancanza di tempo. In altre parole, nel corso dei primi anni il prodotto è stato sviluppato da solo una manciata di persone fuori dalle loro rispettive profondità tecnici, con troppo lavoro da fare e non abbastanza tempo per farlo, o abbastanza sonno per quella materia.
Ma l'applicazione rende i mucchi aziendali di soldi, quindi va bene ... giusto?
Urrà per codici hash!
Mentre confronto di base all'attuazione hashing e uguaglianza nella classe Object non consente contenitori come il NET HashSet <> per lavorare con qualsiasi tipo senza alcuna preparazione particolare per la classe di valore, è anche la fonte di una miriade di (a volte sottili) bug del software: Se GetHashCode viene ignorato, una coerente attuazione di Equals solito deve anche essere fornita (e viceversa), e se l'uguaglianza dipende lo stato dell'oggetto (che è, il più delle volte), l'oggetto deve essere immutabile (perché il codice hash deve essere).
Naturalmente, non ogni programmatore conosce le sottigliezze dei gemelli speciali GetHashCode e Equals. E perché dovrebbero? Uno non deve gravare il proprio sé con tutta questa complessità per godersi semplicemente il fatto che qualsiasi tipo può essere messo all'interno di un HashSet, o utilizzato come tipo di chiave in un dizionario - per quella materia - proprio come il predecessore di Robert a quanto pare ha fatto.
Pubblicità
Quando il refactoring del codice vecchio (o, piuttosto, delicatamente lobotomizing con una motosega virtuale), ha trovato questo:
Dictionary <Dictionary <string, string>, Dictionary <string, stringa >> projectAttributes = new Dictionary <Dictionary <string, string>, Dictionary <string, string >> ();
...
Dictionary <string, string> newAttributes = ProjectUpdate.GetMappingAttributes (projectObject);
Dictionary <string, string> savedAttributes = ProjectUpdate.SaveMappingAttributes (projectObject);
projectAttributes.Add (newAttributes, savedAttributes);
...
ritorno projectAttributes;
Robert era incuriosito. A Dictionary (la versione NET di un array associativo) di dizionario per vocabolario? O forse ... un dizionario Meta . Aveva, naturalmente, già visto un po 'di codice "interessanti" nel corso della sua carriera, ma questo era nuovo e lui non riusciva a capire quale sia lo scopo di tale costrutto potrebbe essere. Cioè, fino a quando Robert ha trovato il luogo in cui è stato utilizzato.
! Coppie chiave-valore FTW
è scoperto, il predecessore di Robert stavano cercando un tipo di dati tupla, e nel buon ol 'giorni della Microsoft.NET Framework 3.5, non c'era nessuno - almeno non built-in. Così, naturalmente, la possibilità di fare le proprie cose, tuttavia, che possa essere, era spalancata:
Dictionary <Dictionary <string, string>, Dictionary <string, string >> projectAttributes =
Arguments.Attributes come Dictionary <Dictionary <string, string>, Dictionary <string, string >>;
...
foreach (KeyValuePair <Dictionary <string, string>, Dictionary <string, string >>
projAttributes in projectAttributes)
{
newProjAttributes = projAttributes.Key come Dictionary <string, string>;
savedProjAttributes = projAttributes.Value come Dictionary <string, string>;
}
Robert pensò la logica attraverso per un minuto - che cosa è un 2-tuple diverso da una coppia chiave-valore? E che cosa è un array associativo diverso da una lista di coppie chiave-valore? E che cosa è un singolo valore diverso da una lista con una sola voce? (E che cosa è un ciclo foreach oltre che una voce diversa da chiamare prima?)
Guardando la cosa da questo punto di vista, quasi diventa la cosa più naturale di utilizzare un dizionario con precisione una voce come una 2-tuple. Quasi.
Ancora una volta, tutta questa gioia è possibile solo perché ogni tipo NET implementa GetHashCode. A volte, Robert ancora si chiede se i creatori del NET Framework veramente pensato a quello che le cose che avrebbero aiutato a scatenare sul mondo del codice sorgente.
Di Mark Bowytz2014/09/29
Poiché atterraggio a Ventozoom sei mesi indietro, Robert ha lavorato su una singola applicazione - un'applicazione NET piuttosto complesso, con una base di codice criptico da abbinare. Dice di essere responsabile di diversi separazioni dei dipendenti, è il tipo di applicazione che ha iniziato la vita come una soluzione mod-sporco e veloce innocente per un piccolo gruppo di clienti che, con l'aiuto di un team di aggressivi ragazzi di vendita, rapidamente cresciuti.
E con il numero di clienti, così è cresciuto richieste di nuove funzionalità.
Aggiungere alla miscela risultante dei requisiti mutevoli e funzionalità di scorrimento, i soliti ingredienti di cui avete bisogno per trasformare un problema in una davvero grande casino strisciato via: mancanza di manodopera, la mancanza di competenza nel manodopera disponibile e, ultimo ma non meno importante, la mancanza di tempo. In altre parole, nel corso dei primi anni il prodotto è stato sviluppato da solo una manciata di persone fuori dalle loro rispettive profondità tecnici, con troppo lavoro da fare e non abbastanza tempo per farlo, o abbastanza sonno per quella materia.
Ma l'applicazione rende i mucchi aziendali di soldi, quindi va bene ... giusto?
Urrà per codici hash!
Mentre confronto di base all'attuazione hashing e uguaglianza nella classe Object non consente contenitori come il NET HashSet <> per lavorare con qualsiasi tipo senza alcuna preparazione particolare per la classe di valore, è anche la fonte di una miriade di (a volte sottili) bug del software: Se GetHashCode viene ignorato, una coerente attuazione di Equals solito deve anche essere fornita (e viceversa), e se l'uguaglianza dipende lo stato dell'oggetto (che è, il più delle volte), l'oggetto deve essere immutabile (perché il codice hash deve essere).
Naturalmente, non ogni programmatore conosce le sottigliezze dei gemelli speciali GetHashCode e Equals. E perché dovrebbero? Uno non deve gravare il proprio sé con tutta questa complessità per godersi semplicemente il fatto che qualsiasi tipo può essere messo all'interno di un HashSet, o utilizzato come tipo di chiave in un dizionario - per quella materia - proprio come il predecessore di Robert a quanto pare ha fatto.
Pubblicità
Quando il refactoring del codice vecchio (o, piuttosto, delicatamente lobotomizing con una motosega virtuale), ha trovato questo:
Dictionary <Dictionary <string, string>, Dictionary <string, stringa >> projectAttributes = new Dictionary <Dictionary <string, string>, Dictionary <string, string >> ();
...
Dictionary <string, string> newAttributes = ProjectUpdate.GetMappingAttributes (projectObject);
Dictionary <string, string> savedAttributes = ProjectUpdate.SaveMappingAttributes (projectObject);
projectAttributes.Add (newAttributes, savedAttributes);
...
ritorno projectAttributes;
Robert era incuriosito. A Dictionary (la versione NET di un array associativo) di dizionario per vocabolario? O forse ... un dizionario Meta . Aveva, naturalmente, già visto un po 'di codice "interessanti" nel corso della sua carriera, ma questo era nuovo e lui non riusciva a capire quale sia lo scopo di tale costrutto potrebbe essere. Cioè, fino a quando Robert ha trovato il luogo in cui è stato utilizzato.
! Coppie chiave-valore FTW
è scoperto, il predecessore di Robert stavano cercando un tipo di dati tupla, e nel buon ol 'giorni della Microsoft.NET Framework 3.5, non c'era nessuno - almeno non built-in. Così, naturalmente, la possibilità di fare le proprie cose, tuttavia, che possa essere, era spalancata:
Dictionary <Dictionary <string, string>, Dictionary <string, string >> projectAttributes =
Arguments.Attributes come Dictionary <Dictionary <string, string>, Dictionary <string, string >>;
...
foreach (KeyValuePair <Dictionary <string, string>, Dictionary <string, string >>
projAttributes in projectAttributes)
{
newProjAttributes = projAttributes.Key come Dictionary <string, string>;
savedProjAttributes = projAttributes.Value come Dictionary <string, string>;
}
Robert pensò la logica attraverso per un minuto - che cosa è un 2-tuple diverso da una coppia chiave-valore? E che cosa è un array associativo diverso da una lista di coppie chiave-valore? E che cosa è un singolo valore diverso da una lista con una sola voce? (E che cosa è un ciclo foreach oltre che una voce diversa da chiamare prima?)
Guardando la cosa da questo punto di vista, quasi diventa la cosa più naturale di utilizzare un dizionario con precisione una voce come una 2-tuple. Quasi.
Ancora una volta, tutta questa gioia è possibile solo perché ogni tipo NET implementa GetHashCode. A volte, Robert ancora si chiede se i creatori del NET Framework veramente pensato a quello che le cose che avrebbero aiutato a scatenare sul mondo del codice sorgente.
giovedì 18 settembre 2014
Tabelle Dividere in Entity Framework 6 per migliorare le prestazioni
ICi sono alcune occasioni quando si utilizza Entity Framework può davvero farti del male: Quando si dispone di tabelle con centinaia di colonne o tabelle con grandi carichi utili. Ecco come ottenere EF6 di fare la cosa giusta.
By Peter Vogel2014/09/17
La prima regola di accelerare l'applicazione è "Gestione accesso al database." Purtroppo, utilizzando Entity Framework (EF) significa rinunciare a qualche controllo intorno gestire l'accesso - in particolare, nel generare SQL. Come lettore ha sottolineato in un recente articolo , prendendo tutte le impostazioni predefinite di EF può risultare in un'applicazione che viene eseguita molto lentamente, anzi.
La questione sollevata è il lettore che, per impostazione predefinita, Entity Framework genera le istruzioni SQL per recuperare tutte le colonne che corrispondono alle proprietà sulle vostre classi di entità. Spesso, che saranno più dati del necessario. Ci stanno per essere momenti in cui, per esempio, invece si è dati da prima e l'ultima colonna di un cliente, ma l'entità che si sta utilizzando ha molte più proprietà che solo quei due colonne. Entity Framework, non essendo in grado di leggere la tua mente, recupererà le colonne della tabella che corrispondono a ogni proprietà sulla vostra entità, non solo i nomi e cognomi.
Mentre, sulla faccia di esso, che sembra inefficiente, il risultato di solito cade in un "nessun danno, nessun fallo" zona: Probabilmente non può misurare la differenza tra recupero solo le due colonne che si desidera e recuperare tutte le colonne.
Quando si potrebbe avere un problema
, ma per fare che "nessun danno, nessun fallo" reclamo, devo fare tre ipotesi. In primo luogo, sto supponendo che si sta costruendo un'applicazione online transazionale dove non recuperare molte righe alla volta (tipicamente, meno di una decina di righe) - cioè, "valore di transazione" una di righe. Poiché il numero di righe aumenta, alla fine la differenza tra ottenere due colonne e ottenere "tutte le colonne" recuperate diventerà abbastanza grande per fare la differenza. Tuttavia, la mia ipotesi sta per essere vero in quasi tutti i casi: Entity Framework è rivolto verso applicazioni online transazionali - non dovrebbe essere utilizzato per l'elaborazione in batch o applicazioni dove stai di elaborazione di centinaia o migliaia di righe alla volta di reporting .
Le mie altre due ipotesi sono ragionevoli, ma, a differenza mia prima ipotesi, non è sempre vero. Il secondo presupposto è che "tutte le colonne" è un numero piccolo - un paio di dozzine di colonne, per esempio. Se si dispone di una tabella con centinaia di colonne, allora è certamente possibile che si noterà la differenza tra il recupero di alcune colonne e il recupero "tutte le colonne," anche se si desidera recuperare solo un "valore di transazione" di righe.
La mia terza ipotesi è che la tabella non include alcun oggetto di grandi dimensioni (BLOB) colonne binarie (in Microsoft SQL Server, queste sono le colonne con i tipi varbinary, di immagine e di dati xml). Se si dispone di una colonna blob definito nella classe entità e stanno recuperando quella colonna quando non si desidera che allora si potrebbe facilmente avere un problema di prestazioni (anche se molto dipenderà anche da quanto è grande l'oggetto memorizzato nella colonna blob è) . E 'anche possibile che si può avere un problema se si dispone di grandi colonne di caratteri abbastanza oggetti (clob: testo, ntext, nvarchar (max), testo, varchar (max)).
In questi scenari, tuttavia, la correzione al vostro problema è sufficientemente semplice e probabilmente sufficientemente localizzate che non vorrei applicarla. Invece, mi piacerebbe costruire l'applicazione con un oggetto entità semplice che recupera tutte le colonne e vedere se il rendimento è accettabile. Solo se non stai ricevendo le prestazioni che si desidera si deve applicare la seguente correzione alle parti interessate della vostra applicazione.
Risolvere il problema
in modo efficace, si desidera implementare due modelli di recupero dei dati quando ottenere i dati dalle colonne che compongono le tabelle problema. Per la maggior parte delle proprietà sul vostro oggetto entità, si desidera che il valore predefinito Entity Framework: eager loading. Con eager loading, i dati della colonna vengono recuperati quando si elabora l'oggetto entità.
Per le colonne BLOB (o per le centinaia di colonne non è necessario) che si desidera un approccio diverso: lazy loading. Con lazy loading, i dati vengono recuperati dalla colonna quando si leggono le proprietà corrispondenti, non quando si tocca l'entità. Purtroppo, Entity Framework non dispone di un attributo LazyLoading che è possibile applicare alle proprietà di rinviare il recupero dei loro dati.
Tuttavia, Entity Framework supporta il caricamento lazy tra le entità di business che sono collegati attraverso una associazione. Sfruttando questa caratteristica è possibile ottenere il risultato desiderato, dividendo il vostro tavolo tra due o più entità unite da una associazione.
Con il vostro tavolo diviso in due (o più) entità collegate è possibile recuperare le proprietà desiderate ardentemente e pigramente rinviare recuperare le proprietà che non si desidera fino a quando ne avete bisogno. Avrete bisogno di almeno due soggetti: uno con le colonne che si desidera recuperare avidamente; e uno sull'altro lato di una associazione, con le proprietà Potrai recuperare pigramente. Per le "centinaia di colonne" problema, è necessario guardare la vostra applicazione per decidere quali colonne si utilizza insieme e gruppo di proprietà tuoi entità 'a sostegno di tale uso.
Per questo esempio, ho intenzione di prendere il più facile dei due problemi e guardare una tabella che ha una colonna blob. Ho modificato il database di Microsoft AdventureWorks quindi la tabella Customers contiene una colonna chiamata Picture immagine di tipo (presumibilmente questo vale una foto del cliente). In questa colonna, ho intenzione di implementare questa soluzione Codice First utilizzando EF6. (Tornerò a questo problema a fine mese di risolverlo utilizzando il progettista EF.)
Un codice prima soluzione
Nel codice prima soluzione scrivo le mie due classi di entità Cliente e segregare mia proprietà Picture (che voglio caricare pigramente) dalle proprietà che voglio caricare con entusiasmo. Entrambe le classi devono avere proprietà ID del cliente, che identifica un cliente. Le due classi hanno questo aspetto, inizialmente:
Public Class CustomerEager
<Key>
ID proprietà pubblica As Integer
Public Property Cognome As String
... Resto di proprietà ...
End Class
Public Class CustomerLazy
<Key>
ID proprietà pubblica As Integer
Proprietà pubblica Picture As Byte ()
End Class
Il passo successivo è quello di estendere la classe CustomerEager (la classe con le proprietà che voglio maggior parte del tempo), con una proprietà di navigazione che collega all'entità voglio caricare "pigramente". In questo esempio, ho chiamato i CustomerBLOBs proprietà e il tipo di dati restituisce è la mia classe CustomerLazy:
Public Class CustomerEager
<Key>
ID proprietà pubblica As Integer
Public Property Cognome As String
... Resto di proprietà ...
Public Overridable Property CustomerBLOBS Come CustomerLazy
End Class
Nel mio oggetto DbContext, ho intenzione di assumere io accedo solo le mie entità CustomerLazy attraverso la proprietà di navigazione sul mio entità CustomerEager. Come risultato, ho solo bisogno di impostare una proprietà per la mia collezione CustomersEager entità nel mio oggetto DbContext:
Public Class AdventureWorksLTEntitiesRevised
DbContext Inherits
Public Property CustomersEager () Come DbSet (Of CustomerEager)
Il vero lavoro è nello stabilire il rapporto tra le due entità e la tabella che rappresentano. Lo faccio nel mio metodo DbContext OnModelCreating. In primo luogo, dico Entity Framework per generare CustomerLazy e CustomerEager oggetti entità della stessa tabella: Clienti. Questo codice è simile al seguente:
Protected Sub OnModelCreating override (ModelBuilder Come DbModelBuilder)
MyBase.OnModelCreating (ModelBuilder)
modelBuilder.Entity (Of CustomerLazy) (). ToTable ("Clienti")
modelBuilder.Entity (Of CustomerEager) (). ToTable ("Clienti")
Ma, nello stesso metodo, ho anche bisogno di stabilire che l'associazione nell'entità CustomerEager fatta tramite la proprietà CustomerBLOBs ha due caratteristiche. In primo luogo, si tratta di una relazione uno-a-uno con l'oggetto all'altra estremità del rapporto. In secondo luogo, l'oggetto all'estremità dell'altro rapporto è sempre presente. Questo è ciò che fa questo codice:
modelBuilder.Entity (Of CustomerEager).
HasRequired (Function (c) c.CustomerBLOBs).
WithRequiredPrincipal ()
End Sub
Caricamento di impazienza e Pigramente
Con i cambiamenti in atto, ora posso trattare tutti i clienti nel mio database con entusiasmo e recuperare l'immagine solo quando ne ho bisogno (pigramente). Codice come il seguente elaborerà tutti i clienti, solo occasionalmente recuperare l'entità con la proprietà blob:
Dim db As New AdventureWorksLTEntitiesRevised
Per ogni c Come CustomerEager In db.CustomersEager
'... le proprietà di processo CustomerEager ...
Se c.LastName = "Vogel" Allora
'... Processo c.CustomerBLOBs.Photo
End If
Prossimo
Tuttavia, questo codice si tradurrà in due viaggi al database: uno per recuperare l'entità CustomerEager e uno per recuperare i dati CustomerLazy. Questo ha senso quando è necessario solo l'entità pigro rado.
Tuttavia, quando si sa che avete bisogno di i dati provenienti da entrambe le entità, vuoi per evitare che il secondo viaggio al database. In tale scenario, si desidera recuperare il vostro soggetto pigro con entusiasmo (ovviamente, se avete bisogno di tutti i dati per tutto il tempo, non avresti dovuto dividere le tabelle). Entity Framework sarà avidamente caricare il soggetto pigro se si utilizza Entity Framework Includi metodo quando il recupero dell'oggetto ansioso. Includi cause Entity Framework per eseguire un carico desideroso dell'oggetto all'altra estremità della struttura di navigazione il cui nome si passa al metodo Includi. Questo esempio fa un carico desideroso dell'entità
indicato da un terreno CustomerBLOBs dell'entità ansioso:
Dim cust = (da C In db.CustomersEager.Include ("CustomerBLOBs")
Dove c.LastName = "Vogel"
Selezionare c) .Prima
... processo sia CustomerEager e CustomerLazy proprietà
Questi passaggi sono necessari solo se si è in uno dei due scenari che ho descritto all'inizio di questa colonna - e, anche allora, solo se effettivamente avete un problema di prestazioni. E se lo fai, le tabelle di divisione e con il supporto Entity Framework per eager loading e pigro attraverso le associazioni vi darà eager loading dei dati che si desidera e lazy loading dei dati che altrimenti potrebbero danneggiare la vostra performance. In altre parole: tutto quello che volete.
By Peter Vogel2014/09/17
La prima regola di accelerare l'applicazione è "Gestione accesso al database." Purtroppo, utilizzando Entity Framework (EF) significa rinunciare a qualche controllo intorno gestire l'accesso - in particolare, nel generare SQL. Come lettore ha sottolineato in un recente articolo , prendendo tutte le impostazioni predefinite di EF può risultare in un'applicazione che viene eseguita molto lentamente, anzi.
La questione sollevata è il lettore che, per impostazione predefinita, Entity Framework genera le istruzioni SQL per recuperare tutte le colonne che corrispondono alle proprietà sulle vostre classi di entità. Spesso, che saranno più dati del necessario. Ci stanno per essere momenti in cui, per esempio, invece si è dati da prima e l'ultima colonna di un cliente, ma l'entità che si sta utilizzando ha molte più proprietà che solo quei due colonne. Entity Framework, non essendo in grado di leggere la tua mente, recupererà le colonne della tabella che corrispondono a ogni proprietà sulla vostra entità, non solo i nomi e cognomi.
Mentre, sulla faccia di esso, che sembra inefficiente, il risultato di solito cade in un "nessun danno, nessun fallo" zona: Probabilmente non può misurare la differenza tra recupero solo le due colonne che si desidera e recuperare tutte le colonne.
Quando si potrebbe avere un problema
, ma per fare che "nessun danno, nessun fallo" reclamo, devo fare tre ipotesi. In primo luogo, sto supponendo che si sta costruendo un'applicazione online transazionale dove non recuperare molte righe alla volta (tipicamente, meno di una decina di righe) - cioè, "valore di transazione" una di righe. Poiché il numero di righe aumenta, alla fine la differenza tra ottenere due colonne e ottenere "tutte le colonne" recuperate diventerà abbastanza grande per fare la differenza. Tuttavia, la mia ipotesi sta per essere vero in quasi tutti i casi: Entity Framework è rivolto verso applicazioni online transazionali - non dovrebbe essere utilizzato per l'elaborazione in batch o applicazioni dove stai di elaborazione di centinaia o migliaia di righe alla volta di reporting .
Le mie altre due ipotesi sono ragionevoli, ma, a differenza mia prima ipotesi, non è sempre vero. Il secondo presupposto è che "tutte le colonne" è un numero piccolo - un paio di dozzine di colonne, per esempio. Se si dispone di una tabella con centinaia di colonne, allora è certamente possibile che si noterà la differenza tra il recupero di alcune colonne e il recupero "tutte le colonne," anche se si desidera recuperare solo un "valore di transazione" di righe.
La mia terza ipotesi è che la tabella non include alcun oggetto di grandi dimensioni (BLOB) colonne binarie (in Microsoft SQL Server, queste sono le colonne con i tipi varbinary, di immagine e di dati xml). Se si dispone di una colonna blob definito nella classe entità e stanno recuperando quella colonna quando non si desidera che allora si potrebbe facilmente avere un problema di prestazioni (anche se molto dipenderà anche da quanto è grande l'oggetto memorizzato nella colonna blob è) . E 'anche possibile che si può avere un problema se si dispone di grandi colonne di caratteri abbastanza oggetti (clob: testo, ntext, nvarchar (max), testo, varchar (max)).
In questi scenari, tuttavia, la correzione al vostro problema è sufficientemente semplice e probabilmente sufficientemente localizzate che non vorrei applicarla. Invece, mi piacerebbe costruire l'applicazione con un oggetto entità semplice che recupera tutte le colonne e vedere se il rendimento è accettabile. Solo se non stai ricevendo le prestazioni che si desidera si deve applicare la seguente correzione alle parti interessate della vostra applicazione.
Risolvere il problema
in modo efficace, si desidera implementare due modelli di recupero dei dati quando ottenere i dati dalle colonne che compongono le tabelle problema. Per la maggior parte delle proprietà sul vostro oggetto entità, si desidera che il valore predefinito Entity Framework: eager loading. Con eager loading, i dati della colonna vengono recuperati quando si elabora l'oggetto entità.
Per le colonne BLOB (o per le centinaia di colonne non è necessario) che si desidera un approccio diverso: lazy loading. Con lazy loading, i dati vengono recuperati dalla colonna quando si leggono le proprietà corrispondenti, non quando si tocca l'entità. Purtroppo, Entity Framework non dispone di un attributo LazyLoading che è possibile applicare alle proprietà di rinviare il recupero dei loro dati.
Tuttavia, Entity Framework supporta il caricamento lazy tra le entità di business che sono collegati attraverso una associazione. Sfruttando questa caratteristica è possibile ottenere il risultato desiderato, dividendo il vostro tavolo tra due o più entità unite da una associazione.
Con il vostro tavolo diviso in due (o più) entità collegate è possibile recuperare le proprietà desiderate ardentemente e pigramente rinviare recuperare le proprietà che non si desidera fino a quando ne avete bisogno. Avrete bisogno di almeno due soggetti: uno con le colonne che si desidera recuperare avidamente; e uno sull'altro lato di una associazione, con le proprietà Potrai recuperare pigramente. Per le "centinaia di colonne" problema, è necessario guardare la vostra applicazione per decidere quali colonne si utilizza insieme e gruppo di proprietà tuoi entità 'a sostegno di tale uso.
Per questo esempio, ho intenzione di prendere il più facile dei due problemi e guardare una tabella che ha una colonna blob. Ho modificato il database di Microsoft AdventureWorks quindi la tabella Customers contiene una colonna chiamata Picture immagine di tipo (presumibilmente questo vale una foto del cliente). In questa colonna, ho intenzione di implementare questa soluzione Codice First utilizzando EF6. (Tornerò a questo problema a fine mese di risolverlo utilizzando il progettista EF.)
Un codice prima soluzione
Nel codice prima soluzione scrivo le mie due classi di entità Cliente e segregare mia proprietà Picture (che voglio caricare pigramente) dalle proprietà che voglio caricare con entusiasmo. Entrambe le classi devono avere proprietà ID del cliente, che identifica un cliente. Le due classi hanno questo aspetto, inizialmente:
Public Class CustomerEager
<Key>
ID proprietà pubblica As Integer
Public Property Cognome As String
... Resto di proprietà ...
End Class
Public Class CustomerLazy
<Key>
ID proprietà pubblica As Integer
Proprietà pubblica Picture As Byte ()
End Class
Il passo successivo è quello di estendere la classe CustomerEager (la classe con le proprietà che voglio maggior parte del tempo), con una proprietà di navigazione che collega all'entità voglio caricare "pigramente". In questo esempio, ho chiamato i CustomerBLOBs proprietà e il tipo di dati restituisce è la mia classe CustomerLazy:
Public Class CustomerEager
<Key>
ID proprietà pubblica As Integer
Public Property Cognome As String
... Resto di proprietà ...
Public Overridable Property CustomerBLOBS Come CustomerLazy
End Class
Nel mio oggetto DbContext, ho intenzione di assumere io accedo solo le mie entità CustomerLazy attraverso la proprietà di navigazione sul mio entità CustomerEager. Come risultato, ho solo bisogno di impostare una proprietà per la mia collezione CustomersEager entità nel mio oggetto DbContext:
Public Class AdventureWorksLTEntitiesRevised
DbContext Inherits
Public Property CustomersEager () Come DbSet (Of CustomerEager)
Il vero lavoro è nello stabilire il rapporto tra le due entità e la tabella che rappresentano. Lo faccio nel mio metodo DbContext OnModelCreating. In primo luogo, dico Entity Framework per generare CustomerLazy e CustomerEager oggetti entità della stessa tabella: Clienti. Questo codice è simile al seguente:
Protected Sub OnModelCreating override (ModelBuilder Come DbModelBuilder)
MyBase.OnModelCreating (ModelBuilder)
modelBuilder.Entity (Of CustomerLazy) (). ToTable ("Clienti")
modelBuilder.Entity (Of CustomerEager) (). ToTable ("Clienti")
Ma, nello stesso metodo, ho anche bisogno di stabilire che l'associazione nell'entità CustomerEager fatta tramite la proprietà CustomerBLOBs ha due caratteristiche. In primo luogo, si tratta di una relazione uno-a-uno con l'oggetto all'altra estremità del rapporto. In secondo luogo, l'oggetto all'estremità dell'altro rapporto è sempre presente. Questo è ciò che fa questo codice:
modelBuilder.Entity (Of CustomerEager).
HasRequired (Function (c) c.CustomerBLOBs).
WithRequiredPrincipal ()
End Sub
Caricamento di impazienza e Pigramente
Con i cambiamenti in atto, ora posso trattare tutti i clienti nel mio database con entusiasmo e recuperare l'immagine solo quando ne ho bisogno (pigramente). Codice come il seguente elaborerà tutti i clienti, solo occasionalmente recuperare l'entità con la proprietà blob:
Dim db As New AdventureWorksLTEntitiesRevised
Per ogni c Come CustomerEager In db.CustomersEager
'... le proprietà di processo CustomerEager ...
Se c.LastName = "Vogel" Allora
'... Processo c.CustomerBLOBs.Photo
End If
Prossimo
Tuttavia, questo codice si tradurrà in due viaggi al database: uno per recuperare l'entità CustomerEager e uno per recuperare i dati CustomerLazy. Questo ha senso quando è necessario solo l'entità pigro rado.
Tuttavia, quando si sa che avete bisogno di i dati provenienti da entrambe le entità, vuoi per evitare che il secondo viaggio al database. In tale scenario, si desidera recuperare il vostro soggetto pigro con entusiasmo (ovviamente, se avete bisogno di tutti i dati per tutto il tempo, non avresti dovuto dividere le tabelle). Entity Framework sarà avidamente caricare il soggetto pigro se si utilizza Entity Framework Includi metodo quando il recupero dell'oggetto ansioso. Includi cause Entity Framework per eseguire un carico desideroso dell'oggetto all'altra estremità della struttura di navigazione il cui nome si passa al metodo Includi. Questo esempio fa un carico desideroso dell'entità
indicato da un terreno CustomerBLOBs dell'entità ansioso:
Dim cust = (da C In db.CustomersEager.Include ("CustomerBLOBs")
Dove c.LastName = "Vogel"
Selezionare c) .Prima
... processo sia CustomerEager e CustomerLazy proprietà
Questi passaggi sono necessari solo se si è in uno dei due scenari che ho descritto all'inizio di questa colonna - e, anche allora, solo se effettivamente avete un problema di prestazioni. E se lo fai, le tabelle di divisione e con il supporto Entity Framework per eager loading e pigro attraverso le associazioni vi darà eager loading dei dati che si desidera e lazy loading dei dati che altrimenti potrebbero danneggiare la vostra performance. In altre parole: tutto quello che volete.
venerdì 12 settembre 2014
Risolvere la tirannia di HTTP 403 risposte per l'esplorazione delle directory in ASP.NET
L'utente non può saperlo, ma una risposta HTTP 403 quando si naviga ad una directory vuota è un serio rischio per la sicurezza.
Quello che il ?! Vuoi dire che se vado al mio sito che ha una cartella "scripts" dove ho messo tutta la mia JavaScript e io sono l'esplorazione delle directory disattivato (come giustamente dovrebbe) ed il server restituisce un "Forbidden" 403 (che giustamente dovrebbe), I 'sto mettendo le mie cose di internet a rischio di essere pwned ?!
Sì, perché rivela la presenza di una cartella denominata "script", che è una directory comune.
Beh, certo c'è una cartella sanguinosa denominata "script", tutta la mia sorgente HTML che è possibile vedere i riferimenti esso! Potrei chiamarlo "i-love-drunken-elefanti" e si poteva ancora vedere quindi qual è il punto ?!
Ma sarebbe comunque restituire un 403 che confermerebbe l'esistenza della risorsa e rappresentare un rischio directory enumerazione.
Ma si può scoprire la presenza di directory in ogni caso! Ok, in apps moderni come ASP.NET MVC potrebbero in realtà essere percorsi che non si traducono in attraverso percorsi fisici, ma ancora, questo è solo di essere pedante!
Il tuo sito non può andare dal vivo fino a risolvere il problema.
Uh, vorrei solo risolvere che per te ...
Alle prese con il problema di fondo
Questa è una di quelle cose che a torto oa ragione, che ho visto che spuntano da varie squadre di sicurezza e scanner automatici negli ultimi tempi. Si può obiettare che tutto quello che volete (e la gravità di essa è contestata), ma il fatto che alza la sua 'dibattito testa e le cause è sufficiente per risolvere proprio il dannato e da fare con esso. Oh - e per inciso, mi sono imbattuto un Netsparker sopra sono stato pwned? (HIBP) di recente e questo è stato uno dei risultati così yeah, mi colpisce troppo (anche se ho il lusso di scegliere di ignorarlo se mi piace!)
Netsparker segnalare una "risorsa Forbidden" su una cartella con la navigazione diretory disabilitato
Lascia che ti mostri il motivo per cui questo accade: la fonte di ogni pagina ho un tag <script> come questo:
< lo script src = "/ scripts / pwned? v = 2VUGdHR_7X4UImu2rpAgoquGkcvoIBUlzD35P5Y-dgo1"> </ script di >
Questo è in realtà utilizzando bundling e minification ASP.NET per combinare più script in uno e poi schiacciare tutto il codice JavaScript, ma cosa vuol dire è che sta implicando c'è un sentiero che è semplicemente "/ scripts". Se colpiamo percorso che otterremo il seguente:
Il / scripts percorso di ritorno 403
Sì, ho errori personalizzati configurati per l'applicazione, ma non prendo l'403,14 restituito quando l'utente non è autorizzato a sfogliare una directory senza pagina di default presente. Aspetta - qual è il bit .14? Questo è il codice di sub-stato che IIS restituisce per questo particolare sapore di un errore di "proibito". Non si vede il codice di stato secondario riflette esternamente nella risposta, ma esiste all'interno del processo di restituzione.
Troverete lo stesso errore viene restituito per una serie di altri percorsi che sono facilmente individuabili compreso / contenuto, / contenuti / immagini / fonts. Ogni volta che si dispone di una directory, si corre il rischio di un 403,14 da restituire e la gente di sicurezza sempre arrogante.
Un modo per affrontare questo è quello di creare un ingresso URL Rewrite regola tale che ogni richiesta di una cartella vuota conosciuta semplicemente viene espulso al tuo errore predefinito personalizzato o generico pagina 404. Che funziona, ma non è scalabile come si deve farlo per ogni singola cartella compreso quando si aggiungono più tardi su - il quale sarete inevitabilmente dimenticare.
No, qualcosa di più sostenibile si impone.
Facendo la risposta 403 (e perché non si può)
Il mio pensiero originale era questo: io creo una regola di riscrittura URL che cattura l'uscita 403 risposta e semplicemente riscrive a un 302 e aggiunge un'intestazione posizione o in altre parole, dice il browser per reindirizzare fuori alla mia solita pagina 404. Nonostante quanto brillante ho pensato che questa soluzione era, semplicemente non sarebbe giocare a palla. La risposta non veniva catturato dalla regola e il codice di stato non veniva riscritto. In preda alla disperazione, mi rivolsi a Stack Overflow e ha spiegato che io non posso cambiare IIS codice di risposta con URL Rewrite regola di uscita . Ho anche mandato collega MVP e URL Rewrite guru Scott Forsyth .
Potete leggere la risposta di Scott su Stack Overflow, ma insomma, che proprio non andava a lavorare. URL Rewrite non può riscrivere i codici di risposta in modo da qualcos'altro è stato chiamato per. Ci sono probabilmente modi di affrontare questo con un modulo HTTP o da qualche parte all'interno del ciclo di vita della risposta, ma non è una soluzione sola configurazione e ho davvero voluto mantenere questo vincolato a qualcosa che può essere fatto senza ricompilare, semplicemente perché questo è un importante vantaggio per un sacco di gente, soprattutto quando hanno già ottenuto siti web in esecuzione dal vivo e ottengono un risultato come questo.
Ma la soluzione ha cominciato a svilupparsi in risposta di Scott e tutto si riduce a come gli errori vengono gestiti all'interno di system.webServer.
Definizione di errori personalizzati in system.webServer (e come è solo una soluzione parziale)
Ecco la risposta di Stack Overflow che sulla superficie di esso, fa buon senso:
< httpErrors ErrorMode = " Personalizzato " >
< errore statusCode = " 403 " subStatusCode = " 14 " percorso = " / Error / PageNotFound " responseMode = " ExecuteURL " />
</ httpErrors >
Vediamo ora come che guarda su HIBP:
Una pagina "Pagina non trovata" dopo aver configurato un errore HTTP in system.webServer
Ok, se realmente stiamo ottenendo da qualche parte - un pò. Stiamo vedendo "Pagina non trovata", e la richiesta è restituzione di un HTTP 200 che soddisferà il "Noi non vogliono vedere un 403" richieste, ma non è compatibile con un normale 404 sul sito. Per esempio:
Un vero e proprio 404 mostra un reindirizzamento 302
Si potrebbe sostenere che, mentre sì, non c'è più un 403 e che la casella di particolare può essere spuntata, il fatto che l'errore di esplorazione directory restituisce la "Pagina non trovata" pagina sul URL originale con un HTTP 200, mentre la genuina 404 reindirizza a / Errore / PageNotFound rivela effettivamente la stessa cosa di prima - che c'è una cartella fisica denominata "script".
Possiamo cominciare a risolvere il problema abbastanza facilmente modificando l'attributo "responseMode" a "Redirect" invece di "ExecuteUrl". Ecco cosa succede ora:
Reindirizzamento piuttosto che riscrivere l'errore system.webServer
Ah, così va meglio - specie di. Vedere come ora abbiamo la stessa risposta 302 seguito da un reindirizzamento a / Error / PageNotFound - questo è il bello. La cattiva bit è che abbiamo ancora una differenza fondamentale in quanto non c'è stringa di query "aspxerrorpath" quando il reindirizzamento avviene system.webServer. Non è possibile aggiungere neanche, non per la configurazione e né è possibile rimuoverlo dal errore personalizzato che gestisce la genuina 404, almeno non senza aggiustamenti stesso.
Tempo per ottenere creativo.
Rimozione della stringa di query aspxerrorpath
In realtà c'è una soluzione molto semplice per rimuovere la stringa di query dalla configurazione errori personalizzati ed è questo:
< customErrors mode = " On " defaultRedirect = " ~ / Error " >
< errore statusCode = " 404 " redirect = " / Error / PageNotFound? foo = bar " />
</ customErrors >
Che poi significa che il percorso / foo da prima si dà questo:
Appening una stringa di query per non più alla pagina di errore CUSTM passa il valore aspxerror
Che potrebbe sembrare un po 'irregolare (ed è), ma ora si può andare e applicare la stessa stringa di query per il redirect in system.webServer e montone castrato è un vero e proprio 404 o si tratta di un realtà un 403,14, si otterrà lo stesso irregolare stringa di query - lavoro fatto! Non importa ciò che la stringa di query è chiamato ("foo" è puramente casuale) e in effetti non avrete nemmeno bisogno di una coppia nome valore, si può semplicemente aggiungere il punto interrogativo e che da sola è sufficiente.
Il problema, però, è che non mi piace stringhe di query screwy che appaiono nella risposta di no (apparente) buona ragione quindi abbiamo bisogno di un po 'di più a smanettare ancora ...
Riscrivere la posizione redirect
Il problema ora è che voglio prendere / Error / PageNotFound? Foo = bar e di sbarazzarsi della stringa di query. Nel caso in cui la semantica di redirect non sono del tutto familiari, quando un risposte del server web con un 302 come nella schermata afferrare sopra, è anche un colpo di testa "location" che assomiglia a questo:
Località: / Error / PageNotFound foo = bar?
Questo indica al browser di emettere una successiva richiesta di questo percorso, che è il motivo per poi vedere la seconda richiesta di cui sopra. Questo è ciò che dobbiamo cambiare e per fortuna si tratta di una soluzione semplice con URL Rewrite. Sembra proprio come questo:
< outboundRules >
< regola nome = " Modifica intestazione posizione " patternSyntax = " ExactMatch " >
< partita serverVariable = " RESPONSE_location " modello = " / Error / PageNotFound? foo = bar " />
< azione di tipo = " Rewrite " value = " / Error / PageNotFound " />
</ regola >
</ outboundRules >
Roba abbastanza semplice - prendere la "location" intestazione di risposta quando si sta cercando di reindirizzare il browser al nostro percorso di stringa di query irregolare e poi basta spogliarla fuori. Proviamo ora:
La stringa di query "? Foo = bar" ora rimosso dalla risposta
Ehi, questo sembra a posto, ora è esattamente lo stesso del comportamento quando si carica il percorso script! Bastava un errore personalizzato in system.webServer poi una stringa di query irregolare in errore system.web personalizzato per la risposta 404 e una regola di URL Rewrite per modificare il percorso. Come semplice è che ... ?!
Ok, devo essere un po 'faceto, perché dovrebbe essere più facile di quello, ma non è. Il lato positivo, però, ecco quello che abbiamo ora:
Non è più un 403 restituito durante la navigazione di una directory senza pagina di default quando l'esplorazione delle directory è disabilitata C'è.
La risposta da un vero 404 su un percorso inesistente è identica a navigare un percorso fisico senza doc predefinito.
E 'tutto fatto da solo la configurazione, nessun codice.
Quindi è perfetto allora? Beh un pò, tutto tranne che per una piccola cosa ...
Aggira reindirizzamenti di cortesia
Se sei aquila-eyed abbastanza, avrete notato una leggera differenza nel modo in cui ho chiesto foo e script in precedenza con il primo è denominato "/ foo" e quest'ultimo "/ scripts /". Quella barra finale fa una grande differenza, perché ecco cosa succede quando non esiste:
Manca slash causando un HTTP 301 poi un 302
Che follia è questa ?! A 301 "permanente" Redirect seguito da un "temporaneo" 302 redirect e infine la pagina "PageNotFound" - ciò che dà? E 'una cortesia reindirizzamento , cioè IIS è in realtà alla ricerca di un file di denominato "script" e quando non riesce a trovarlo, si rende conto che è c'è una directory con il nome e sputa indietro un 301 dicendo al browser molto esplicitamente che questo è davvero un cartella in virtù della barra finale appena aggiunto. Naturalmente dice anche il signor Hacker la stessa cosa, così mentre il 403 è andato ed i sentieri e le stringhe di query sono tutti buoni, che il reindirizzamento in più dà al gioco via.
Per essere onesti, come circa ora sarete senza dubbio ottenere un segno di spunta dalla gente di sicurezza in quanto non vi è più una 403 Se questo è il vostro obiettivo, allora si può fermare qui, infatti si potrebbe avere arrestato subito dopo il system.webServer voce di errore personalizzato, ma secondo me, che tipo di prova a metà mandato a quel paese. Se ho intenzione di fare questo, ho intenzione di farlo correttamente dannazione!
Sono andato avanti e indietro un po 'con Scott su questo fino a quando siamo venuti a un'implementazione che assomiglia a questo:
< system.webServer >
< defaultDocument abilitato = " true " />
</ system.webServer >
Questo è abbastanza auto-esplicativo - disabilitare la funzionalità di documento predefinito. Ciò significa allora che il DefaultDocumentModule (che è di destra, senza spazi, è una cosa) non causa più la 301 per il percorso con la barra finale, al fine di implicare la richiesta è di una cartella che dovrebbe poi servire il documento predefinito. Significa che la richiesta appare come segue:
A 302 dal percorso script senza slash alla pagina di errore
Significa anche ciascuno dei seguenti scenari risponde in modo identico:
GET https://haveibeenpwned.com/PathDoesntExist
HTTP 302 -> / Error / PageNotFound
GET https://haveibeenpwned.com/PathDoesntExistWithTrailingSlash/
HTTP 302 -> / Error / PageNotFound
GET https://haveibeenpwned.com/scripts
HTTP 302 -> / Error / PageNotFound
GET https://haveibeenpwned.com/scripts/
HTTP 302 -> / Error / PageNotFound
Hallelujah - funziona!
Fatta eccezione per i tempi non è così. In realtà sempre funziona su HIBP, ma che è perché è un app MVC che implementa il routing per mappare un URL come https://haveibeenpwned.com/About al "Chi" controllore. Se fosse un app Web Forms e dipendeva da un file Default.aspx nella "About" directory allora avrei un problema del tutto nuovo.
Tuttavia, ci sono più strade per affrontare questo. Uno è quello di consentire solo i documenti predefiniti per una whitelist di percorsi. Ok, non molto scalabile ma certamente fattibile.
Un altro è quello di utilizzare URL Rewrite per reindirizzare le query ai percorsi specifici che si basano su un documento predefinito per l'URL che contiene esplicitamente il nome del file in esso, ad esempio "/foo/default.aspx". Ancora una volta, non reale scalabile e anche non reale bella.
Una soluzione migliore sarebbe quella di utilizzare la riscrittura URL o in altre parole, impostare la modalità di risposta system.webServer a "ExecuteURL" e gli errori personalizzati reindirizzano alla modalità "ResponseRewrite". Questo sarà quindi mostrare la pagina di errore sul URL richiesto senza alcun reindirizzamento di sorta. Se siete preoccupati per le implicazioni SEO di un HTTP 200 che mostra una pagina di errore, si può sempre cambiare il codice di risposta nella pagina di errore in sé.
Anche in questo caso, è più aggiustamenti, ma che l'ultima opzione è probabilmente la scelta migliore se hai una dipendenza sulla presenza di documenti predefiniti in cartelle.
Riassunto
Se io sono onesto, tutto questo è un sacco di gingillarsi per molto poco beneficio fine. Persone caritatevoli Meno di me lo chiamerei "teatro di sicurezza" e nello spettro di rischi potenzialmente sfruttabili, questo è il modo, in fondo in fondo.
Ma niente di tutto questo cambia il fatto che strumenti di sicurezza e squadre ritengono che questo sia un rischio e solleva una bandiera ed è necessario per risolvere il problema. Che in ultima analisi, può essere fissato molto facilmente (ma solo perché ora avete la strada tracciata per voi!) e tramite la configurazione solo è un buon motivo sufficiente per farlo e andare avanti.
Oh, e nel caso in cui si dispone di un mezzo più efficiente per farlo sia con configurazione o codice, lasciate un commento con alcuni consigli. Questo è il genere di cosa che la gente inevitabilmente Google la loro strada nel più facile e siamo in grado di rendere la vita su coloro che seguono, il migliore.
Giusto per rendere più reale facile, ecco tutte le config in un colpo solo:
< system.web >
< customErrors >
< errore statusCode = " 404 " redirect = " / Error / PageNotFound? foo = bar " />
</ customErrors >
</ system.web >
< system.webServer >
< riscrittura >
< outboundRules >
< regola nome = " Modifica intestazione posizione " patternSyntax = " ExactMatch " >
< partita serverVariable = " RESPONSE_location " modello = " / Error / PageNotFound? foo = bar " />
< azione di tipo = " Rewrite " value = " / Error / PageNotFound " />
</ regola >
</ outboundRules >
</ riscrittura >
< httpErrors ErrorMode = " Personalizzato " >
< errore statusCode = " 403 " subStatusCode = " 14 " percorso = " / Error / PageNotFound " responseMode = " Redirect " />
</ httpErrors >
< defaultDocument abilitato = " true " />
</ system.webServer >
Non, non ti senti più sicuro adesso? :)
Quello che il ?! Vuoi dire che se vado al mio sito che ha una cartella "scripts" dove ho messo tutta la mia JavaScript e io sono l'esplorazione delle directory disattivato (come giustamente dovrebbe) ed il server restituisce un "Forbidden" 403 (che giustamente dovrebbe), I 'sto mettendo le mie cose di internet a rischio di essere pwned ?!
Sì, perché rivela la presenza di una cartella denominata "script", che è una directory comune.
Beh, certo c'è una cartella sanguinosa denominata "script", tutta la mia sorgente HTML che è possibile vedere i riferimenti esso! Potrei chiamarlo "i-love-drunken-elefanti" e si poteva ancora vedere quindi qual è il punto ?!
Ma sarebbe comunque restituire un 403 che confermerebbe l'esistenza della risorsa e rappresentare un rischio directory enumerazione.
Ma si può scoprire la presenza di directory in ogni caso! Ok, in apps moderni come ASP.NET MVC potrebbero in realtà essere percorsi che non si traducono in attraverso percorsi fisici, ma ancora, questo è solo di essere pedante!
Il tuo sito non può andare dal vivo fino a risolvere il problema.
Uh, vorrei solo risolvere che per te ...
Alle prese con il problema di fondo
Questa è una di quelle cose che a torto oa ragione, che ho visto che spuntano da varie squadre di sicurezza e scanner automatici negli ultimi tempi. Si può obiettare che tutto quello che volete (e la gravità di essa è contestata), ma il fatto che alza la sua 'dibattito testa e le cause è sufficiente per risolvere proprio il dannato e da fare con esso. Oh - e per inciso, mi sono imbattuto un Netsparker sopra sono stato pwned? (HIBP) di recente e questo è stato uno dei risultati così yeah, mi colpisce troppo (anche se ho il lusso di scegliere di ignorarlo se mi piace!)
Netsparker segnalare una "risorsa Forbidden" su una cartella con la navigazione diretory disabilitato
Lascia che ti mostri il motivo per cui questo accade: la fonte di ogni pagina ho un tag <script> come questo:
< lo script src = "/ scripts / pwned? v = 2VUGdHR_7X4UImu2rpAgoquGkcvoIBUlzD35P5Y-dgo1"> </ script di >
Questo è in realtà utilizzando bundling e minification ASP.NET per combinare più script in uno e poi schiacciare tutto il codice JavaScript, ma cosa vuol dire è che sta implicando c'è un sentiero che è semplicemente "/ scripts". Se colpiamo percorso che otterremo il seguente:
Il / scripts percorso di ritorno 403
Sì, ho errori personalizzati configurati per l'applicazione, ma non prendo l'403,14 restituito quando l'utente non è autorizzato a sfogliare una directory senza pagina di default presente. Aspetta - qual è il bit .14? Questo è il codice di sub-stato che IIS restituisce per questo particolare sapore di un errore di "proibito". Non si vede il codice di stato secondario riflette esternamente nella risposta, ma esiste all'interno del processo di restituzione.
Troverete lo stesso errore viene restituito per una serie di altri percorsi che sono facilmente individuabili compreso / contenuto, / contenuti / immagini / fonts. Ogni volta che si dispone di una directory, si corre il rischio di un 403,14 da restituire e la gente di sicurezza sempre arrogante.
Un modo per affrontare questo è quello di creare un ingresso URL Rewrite regola tale che ogni richiesta di una cartella vuota conosciuta semplicemente viene espulso al tuo errore predefinito personalizzato o generico pagina 404. Che funziona, ma non è scalabile come si deve farlo per ogni singola cartella compreso quando si aggiungono più tardi su - il quale sarete inevitabilmente dimenticare.
No, qualcosa di più sostenibile si impone.
Facendo la risposta 403 (e perché non si può)
Il mio pensiero originale era questo: io creo una regola di riscrittura URL che cattura l'uscita 403 risposta e semplicemente riscrive a un 302 e aggiunge un'intestazione posizione o in altre parole, dice il browser per reindirizzare fuori alla mia solita pagina 404. Nonostante quanto brillante ho pensato che questa soluzione era, semplicemente non sarebbe giocare a palla. La risposta non veniva catturato dalla regola e il codice di stato non veniva riscritto. In preda alla disperazione, mi rivolsi a Stack Overflow e ha spiegato che io non posso cambiare IIS codice di risposta con URL Rewrite regola di uscita . Ho anche mandato collega MVP e URL Rewrite guru Scott Forsyth .
Potete leggere la risposta di Scott su Stack Overflow, ma insomma, che proprio non andava a lavorare. URL Rewrite non può riscrivere i codici di risposta in modo da qualcos'altro è stato chiamato per. Ci sono probabilmente modi di affrontare questo con un modulo HTTP o da qualche parte all'interno del ciclo di vita della risposta, ma non è una soluzione sola configurazione e ho davvero voluto mantenere questo vincolato a qualcosa che può essere fatto senza ricompilare, semplicemente perché questo è un importante vantaggio per un sacco di gente, soprattutto quando hanno già ottenuto siti web in esecuzione dal vivo e ottengono un risultato come questo.
Ma la soluzione ha cominciato a svilupparsi in risposta di Scott e tutto si riduce a come gli errori vengono gestiti all'interno di system.webServer.
Definizione di errori personalizzati in system.webServer (e come è solo una soluzione parziale)
Ecco la risposta di Stack Overflow che sulla superficie di esso, fa buon senso:
< httpErrors ErrorMode = " Personalizzato " >
< errore statusCode = " 403 " subStatusCode = " 14 " percorso = " / Error / PageNotFound " responseMode = " ExecuteURL " />
</ httpErrors >
Vediamo ora come che guarda su HIBP:
Una pagina "Pagina non trovata" dopo aver configurato un errore HTTP in system.webServer
Ok, se realmente stiamo ottenendo da qualche parte - un pò. Stiamo vedendo "Pagina non trovata", e la richiesta è restituzione di un HTTP 200 che soddisferà il "Noi non vogliono vedere un 403" richieste, ma non è compatibile con un normale 404 sul sito. Per esempio:
Un vero e proprio 404 mostra un reindirizzamento 302
Si potrebbe sostenere che, mentre sì, non c'è più un 403 e che la casella di particolare può essere spuntata, il fatto che l'errore di esplorazione directory restituisce la "Pagina non trovata" pagina sul URL originale con un HTTP 200, mentre la genuina 404 reindirizza a / Errore / PageNotFound rivela effettivamente la stessa cosa di prima - che c'è una cartella fisica denominata "script".
Possiamo cominciare a risolvere il problema abbastanza facilmente modificando l'attributo "responseMode" a "Redirect" invece di "ExecuteUrl". Ecco cosa succede ora:
Reindirizzamento piuttosto che riscrivere l'errore system.webServer
Ah, così va meglio - specie di. Vedere come ora abbiamo la stessa risposta 302 seguito da un reindirizzamento a / Error / PageNotFound - questo è il bello. La cattiva bit è che abbiamo ancora una differenza fondamentale in quanto non c'è stringa di query "aspxerrorpath" quando il reindirizzamento avviene system.webServer. Non è possibile aggiungere neanche, non per la configurazione e né è possibile rimuoverlo dal errore personalizzato che gestisce la genuina 404, almeno non senza aggiustamenti stesso.
Tempo per ottenere creativo.
Rimozione della stringa di query aspxerrorpath
In realtà c'è una soluzione molto semplice per rimuovere la stringa di query dalla configurazione errori personalizzati ed è questo:
< customErrors mode = " On " defaultRedirect = " ~ / Error " >
< errore statusCode = " 404 " redirect = " / Error / PageNotFound? foo = bar " />
</ customErrors >
Che poi significa che il percorso / foo da prima si dà questo:
Appening una stringa di query per non più alla pagina di errore CUSTM passa il valore aspxerror
Che potrebbe sembrare un po 'irregolare (ed è), ma ora si può andare e applicare la stessa stringa di query per il redirect in system.webServer e montone castrato è un vero e proprio 404 o si tratta di un realtà un 403,14, si otterrà lo stesso irregolare stringa di query - lavoro fatto! Non importa ciò che la stringa di query è chiamato ("foo" è puramente casuale) e in effetti non avrete nemmeno bisogno di una coppia nome valore, si può semplicemente aggiungere il punto interrogativo e che da sola è sufficiente.
Il problema, però, è che non mi piace stringhe di query screwy che appaiono nella risposta di no (apparente) buona ragione quindi abbiamo bisogno di un po 'di più a smanettare ancora ...
Riscrivere la posizione redirect
Il problema ora è che voglio prendere / Error / PageNotFound? Foo = bar e di sbarazzarsi della stringa di query. Nel caso in cui la semantica di redirect non sono del tutto familiari, quando un risposte del server web con un 302 come nella schermata afferrare sopra, è anche un colpo di testa "location" che assomiglia a questo:
Località: / Error / PageNotFound foo = bar?
Questo indica al browser di emettere una successiva richiesta di questo percorso, che è il motivo per poi vedere la seconda richiesta di cui sopra. Questo è ciò che dobbiamo cambiare e per fortuna si tratta di una soluzione semplice con URL Rewrite. Sembra proprio come questo:
< outboundRules >
< regola nome = " Modifica intestazione posizione " patternSyntax = " ExactMatch " >
< partita serverVariable = " RESPONSE_location " modello = " / Error / PageNotFound? foo = bar " />
< azione di tipo = " Rewrite " value = " / Error / PageNotFound " />
</ regola >
</ outboundRules >
Roba abbastanza semplice - prendere la "location" intestazione di risposta quando si sta cercando di reindirizzare il browser al nostro percorso di stringa di query irregolare e poi basta spogliarla fuori. Proviamo ora:
La stringa di query "? Foo = bar" ora rimosso dalla risposta
Ehi, questo sembra a posto, ora è esattamente lo stesso del comportamento quando si carica il percorso script! Bastava un errore personalizzato in system.webServer poi una stringa di query irregolare in errore system.web personalizzato per la risposta 404 e una regola di URL Rewrite per modificare il percorso. Come semplice è che ... ?!
Ok, devo essere un po 'faceto, perché dovrebbe essere più facile di quello, ma non è. Il lato positivo, però, ecco quello che abbiamo ora:
Non è più un 403 restituito durante la navigazione di una directory senza pagina di default quando l'esplorazione delle directory è disabilitata C'è.
La risposta da un vero 404 su un percorso inesistente è identica a navigare un percorso fisico senza doc predefinito.
E 'tutto fatto da solo la configurazione, nessun codice.
Quindi è perfetto allora? Beh un pò, tutto tranne che per una piccola cosa ...
Aggira reindirizzamenti di cortesia
Se sei aquila-eyed abbastanza, avrete notato una leggera differenza nel modo in cui ho chiesto foo e script in precedenza con il primo è denominato "/ foo" e quest'ultimo "/ scripts /". Quella barra finale fa una grande differenza, perché ecco cosa succede quando non esiste:
Manca slash causando un HTTP 301 poi un 302
Che follia è questa ?! A 301 "permanente" Redirect seguito da un "temporaneo" 302 redirect e infine la pagina "PageNotFound" - ciò che dà? E 'una cortesia reindirizzamento , cioè IIS è in realtà alla ricerca di un file di denominato "script" e quando non riesce a trovarlo, si rende conto che è c'è una directory con il nome e sputa indietro un 301 dicendo al browser molto esplicitamente che questo è davvero un cartella in virtù della barra finale appena aggiunto. Naturalmente dice anche il signor Hacker la stessa cosa, così mentre il 403 è andato ed i sentieri e le stringhe di query sono tutti buoni, che il reindirizzamento in più dà al gioco via.
Per essere onesti, come circa ora sarete senza dubbio ottenere un segno di spunta dalla gente di sicurezza in quanto non vi è più una 403 Se questo è il vostro obiettivo, allora si può fermare qui, infatti si potrebbe avere arrestato subito dopo il system.webServer voce di errore personalizzato, ma secondo me, che tipo di prova a metà mandato a quel paese. Se ho intenzione di fare questo, ho intenzione di farlo correttamente dannazione!
Sono andato avanti e indietro un po 'con Scott su questo fino a quando siamo venuti a un'implementazione che assomiglia a questo:
< system.webServer >
< defaultDocument abilitato = " true " />
</ system.webServer >
Questo è abbastanza auto-esplicativo - disabilitare la funzionalità di documento predefinito. Ciò significa allora che il DefaultDocumentModule (che è di destra, senza spazi, è una cosa) non causa più la 301 per il percorso con la barra finale, al fine di implicare la richiesta è di una cartella che dovrebbe poi servire il documento predefinito. Significa che la richiesta appare come segue:
A 302 dal percorso script senza slash alla pagina di errore
Significa anche ciascuno dei seguenti scenari risponde in modo identico:
GET https://haveibeenpwned.com/PathDoesntExist
HTTP 302 -> / Error / PageNotFound
GET https://haveibeenpwned.com/PathDoesntExistWithTrailingSlash/
HTTP 302 -> / Error / PageNotFound
GET https://haveibeenpwned.com/scripts
HTTP 302 -> / Error / PageNotFound
GET https://haveibeenpwned.com/scripts/
HTTP 302 -> / Error / PageNotFound
Hallelujah - funziona!
Fatta eccezione per i tempi non è così. In realtà sempre funziona su HIBP, ma che è perché è un app MVC che implementa il routing per mappare un URL come https://haveibeenpwned.com/About al "Chi" controllore. Se fosse un app Web Forms e dipendeva da un file Default.aspx nella "About" directory allora avrei un problema del tutto nuovo.
Tuttavia, ci sono più strade per affrontare questo. Uno è quello di consentire solo i documenti predefiniti per una whitelist di percorsi. Ok, non molto scalabile ma certamente fattibile.
Un altro è quello di utilizzare URL Rewrite per reindirizzare le query ai percorsi specifici che si basano su un documento predefinito per l'URL che contiene esplicitamente il nome del file in esso, ad esempio "/foo/default.aspx". Ancora una volta, non reale scalabile e anche non reale bella.
Una soluzione migliore sarebbe quella di utilizzare la riscrittura URL o in altre parole, impostare la modalità di risposta system.webServer a "ExecuteURL" e gli errori personalizzati reindirizzano alla modalità "ResponseRewrite". Questo sarà quindi mostrare la pagina di errore sul URL richiesto senza alcun reindirizzamento di sorta. Se siete preoccupati per le implicazioni SEO di un HTTP 200 che mostra una pagina di errore, si può sempre cambiare il codice di risposta nella pagina di errore in sé.
Anche in questo caso, è più aggiustamenti, ma che l'ultima opzione è probabilmente la scelta migliore se hai una dipendenza sulla presenza di documenti predefiniti in cartelle.
Riassunto
Se io sono onesto, tutto questo è un sacco di gingillarsi per molto poco beneficio fine. Persone caritatevoli Meno di me lo chiamerei "teatro di sicurezza" e nello spettro di rischi potenzialmente sfruttabili, questo è il modo, in fondo in fondo.
Ma niente di tutto questo cambia il fatto che strumenti di sicurezza e squadre ritengono che questo sia un rischio e solleva una bandiera ed è necessario per risolvere il problema. Che in ultima analisi, può essere fissato molto facilmente (ma solo perché ora avete la strada tracciata per voi!) e tramite la configurazione solo è un buon motivo sufficiente per farlo e andare avanti.
Oh, e nel caso in cui si dispone di un mezzo più efficiente per farlo sia con configurazione o codice, lasciate un commento con alcuni consigli. Questo è il genere di cosa che la gente inevitabilmente Google la loro strada nel più facile e siamo in grado di rendere la vita su coloro che seguono, il migliore.
Giusto per rendere più reale facile, ecco tutte le config in un colpo solo:
< system.web >
< customErrors >
< errore statusCode = " 404 " redirect = " / Error / PageNotFound? foo = bar " />
</ customErrors >
</ system.web >
< system.webServer >
< riscrittura >
< outboundRules >
< regola nome = " Modifica intestazione posizione " patternSyntax = " ExactMatch " >
< partita serverVariable = " RESPONSE_location " modello = " / Error / PageNotFound? foo = bar " />
< azione di tipo = " Rewrite " value = " / Error / PageNotFound " />
</ regola >
</ outboundRules >
</ riscrittura >
< httpErrors ErrorMode = " Personalizzato " >
< errore statusCode = " 403 " subStatusCode = " 14 " percorso = " / Error / PageNotFound " responseMode = " Redirect " />
</ httpErrors >
< defaultDocument abilitato = " true " />
</ system.webServer >
Non, non ti senti più sicuro adesso? :)
lunedì 8 settembre 2014
Di Visual F # Include Windows Phone 8.1 a sostegno Biblioteca Portable
La versione 3.1.2 di Microsoft F # derivazione ha ampliato il supporto biblioteca portatile e permette l'opzione Pubblica in progetti Web e Azure.
By Michael Domingo2014/09/03
Visual F # team di Microsoft blogged circa un rilascio minore di F # che "confeziona gli ultimi aggiornamenti per il compilatore F #, interattivo, tempo di esecuzione, e l'integrazione di Visual Studio." Di Visual F # 3.1.2 arriva poco dopo un out-of-band 3.1.1 rilascio nel mese di gennaio che ha aggiunto il supporto per Desktop e Web Express.
Di Visual F # è la versione Microsoft di F #, un linguaggio di programmazione fortemente tipizzato derivato da ML che è fortemente influenzato da C # e Python. F # si supporta un certo numero di stili di programmazione, tra cui object-oriented, funzionale, e linguaggi procedurali, ed è anche in grado di generare codice in JavaScript e per l'utilizzo con le GPU. Di Visual F # è un'estensione di quella lingua che può lavorare entro i confini della Microsoft NET Framework. (Una definizione approfondita della lingua può essere trovato sul MSDN Library .
La release 3.1.2 punto aggiunge una manciata di caratteristiche nuove e utili, tra cui il supporto biblioteca portatile esteso. Questa si presenta sotto forma di modelli di progetto F # che supportano il profilo 78 e profilo 259 profili portatili, entrambi i quali supportano Windows Phone 8.1. Il risultato è che le biblioteche portatili F # possono essere aggiunti a Windows Phone 8.1 progetti direttamente.
Un altro cambiamento significativo osservato nel blog ha a che fare con il flusso di lavoro. In particolare, questa versione di Visual F # supporta non-bloccaggio #r riferimenti mentre si lavora con Visual F # interattiva in uno sviluppo rapido-iterazione. Riferimenti di montaggio sono attivati per impostazione predefinita e gli sviluppatori tendono a incontrare gli errori perché, quando uno sviluppatore aggiunge un riferimento all'assembly #r, si blocca che il montaggio su disco. Tutto ciò che serve per configurare come un riferimento a un assembly non-bloccaggio è quello di consentire con l'+ interruttore shadowcopyreferences.
Altri aggiornamenti includono la possibilità di pubblicare i progetti F # Web e Microsoft Azure direttamente da Visual Studio, e alcune modifiche linguistiche minori: migliorata la compatibilità Unix con la possibilità di utilizzare le direttive baracca in F # script (da non confondere con la compatibilità William Hung ), il supporto per affettare alto-dimensionale in codice compilato, e il supporto per gli spazi nei identificatori di casi modello attive.
By Michael Domingo2014/09/03
Visual F # team di Microsoft blogged circa un rilascio minore di F # che "confeziona gli ultimi aggiornamenti per il compilatore F #, interattivo, tempo di esecuzione, e l'integrazione di Visual Studio." Di Visual F # 3.1.2 arriva poco dopo un out-of-band 3.1.1 rilascio nel mese di gennaio che ha aggiunto il supporto per Desktop e Web Express.
Di Visual F # è la versione Microsoft di F #, un linguaggio di programmazione fortemente tipizzato derivato da ML che è fortemente influenzato da C # e Python. F # si supporta un certo numero di stili di programmazione, tra cui object-oriented, funzionale, e linguaggi procedurali, ed è anche in grado di generare codice in JavaScript e per l'utilizzo con le GPU. Di Visual F # è un'estensione di quella lingua che può lavorare entro i confini della Microsoft NET Framework. (Una definizione approfondita della lingua può essere trovato sul MSDN Library .
La release 3.1.2 punto aggiunge una manciata di caratteristiche nuove e utili, tra cui il supporto biblioteca portatile esteso. Questa si presenta sotto forma di modelli di progetto F # che supportano il profilo 78 e profilo 259 profili portatili, entrambi i quali supportano Windows Phone 8.1. Il risultato è che le biblioteche portatili F # possono essere aggiunti a Windows Phone 8.1 progetti direttamente.
Un altro cambiamento significativo osservato nel blog ha a che fare con il flusso di lavoro. In particolare, questa versione di Visual F # supporta non-bloccaggio #r riferimenti mentre si lavora con Visual F # interattiva in uno sviluppo rapido-iterazione. Riferimenti di montaggio sono attivati per impostazione predefinita e gli sviluppatori tendono a incontrare gli errori perché, quando uno sviluppatore aggiunge un riferimento all'assembly #r, si blocca che il montaggio su disco. Tutto ciò che serve per configurare come un riferimento a un assembly non-bloccaggio è quello di consentire con l'+ interruttore shadowcopyreferences.
Altri aggiornamenti includono la possibilità di pubblicare i progetti F # Web e Microsoft Azure direttamente da Visual Studio, e alcune modifiche linguistiche minori: migliorata la compatibilità Unix con la possibilità di utilizzare le direttive baracca in F # script (da non confondere con la compatibilità William Hung ), il supporto per affettare alto-dimensionale in codice compilato, e il supporto per gli spazi nei identificatori di casi modello attive.
martedì 2 settembre 2014
Creazione personalizzati HttpClient gestori
Accesso alle API Web può essere fatto facilmente utilizzando il gestore HTTPClient. Questa classe accelera il processo di sviluppo di accedere ai dati da un Web API, e consente di personalizzare i gestori cliente in caso di necessità.
HTTPClient è un oggetto utilizzato per l'accesso di richiesta e risposta dei messaggi da e verso API web. Come chiamate client-server tradizionali, la HTTPClient chiama il server utilizzando uno specifico URI, aspetta il risultato, quindi restituisce un oggetto risposta al chiamante.
Come per tutto il resto nello sviluppo di software, la necessità finirà per sorgere per lo sviluppo personalizzato. Per fortuna, la classe HttpClient consente per questo. Un gestore di messaggi singolo, o un numero di gestori, possono essere creati e aggiunti in un ordine specifico per lo stack di chiamate utilizzando il metodo HttpClientFactory.Create.
Uno o più gestori di messaggi personalizzati possono essere creati e organizzati in una catena di gestori che vengono automaticamente chiamato con ogni richiesta e la risposta. Una volta creata la classe del gestore messaggio, esso può essere utilizzato per eseguire operazioni personalizzate durante la sequenza di chiamata. Osservando lo schema di figura 1 , la sequenza inizia con la richiesta del cliente, poi continua attraverso la catena di gestori. Una volta che il messaggio raggiunge il server, la risposta viene inviata indietro propagazione attraverso la catena dei gestori in ordine inverso.
Figura 1. Flusso dei messaggi per la richiesta del cliente e risposta
Per dimostrare i gestori personalizzati sul cliente, sarà necessaria una API Web per inviare richieste e ricevere risposte da. In un precedente articolo , ho dimostrato come è possibile creare un Web API. Il codice utilizzato in tale articolo servirà come l'API Web per questo articolo, con una piccola modifica. Nel metodo Registro della App_Start \ WebApiConfig.cs di file, aggiungerò la dichiarazione config.Formatters.Add (nuovo JsonMediaTypeFormatter ()) ;. Ciò consentirà l'API Web per formattare i dati di output in formato JSON. Si può vedere il codice completo in Listato 1 .
Listato 1: Contenuto del WebApiConfig.cs (in API Web di progetto) dopo la modifica
Pubblicità
utilizzando System.Net.Http.Formatting;
utilizzando System.Web.Http;
namespace CarInventory21
{
pubblico WebApiConfig classe statica
{
public void Registro static (HttpConfiguration config)
{
// Configurazione e servizi Web API
// percorsi API Web
config.MapHttpAttributeRoutes ();
config.Routes.MapHttpRoute (
Nome: "DefaultApi",
routeTemplate: "api / {comando} / {id}",
default: nuovo {id = RouteParameter.Optional}
);
config.Formatters.Clear (); // Rimuovere tutti gli altri formattatori
config.Formatters.Add (nuovo BsonMediaTypeFormatter ()); // Abilita BSON nel servizio Web
config.Formatters.Add (nuovo JsonMediaTypeFormatter ());
}
}
}
Ora l'API Web è pronto per essere utilizzato con il nuovo demo applicazione client. Per questo, creerò una nuova applicazione Windows Form, come si vede in figura 2 .
[Clicca sull'immagine per ingrandirla.] Figura 2. Creazione di un'applicazione Windows Form come un client API Web
L'interfaccia utente per l'applicazione è mantenuto semplice per scopi dimostrativi, come si vede in Figura 3 L'applicazione client demo è destinato a funzionare da C:. \ WebAPI21ClientDemo.
[Clicca sull'immagine per ingrandirla.] Figura 3. ui per Web Demo Client API
Dopo aver impostato l'interfaccia utente in figura 3 , io aggiungo la classe Car ai frmMain.cs. La classe Car è un modello dei dati ricevuti dalla chiamata API web. E 'lo stesso modello utilizzato nel progetto Web API. Assicurarsi di aggiungere questo dopo la frmMain classe nello spazio dei nomi CarInventory21Client del file frmMain.cs. In caso contrario, verrà visualizzato un errore quando si tenta di visualizzare il form designer. Ecco la classe Car:
public class Auto
{
pubblica Int32 ID {get; set; }
pubblica Int32 Anno {get; set; }
stringa di rendere pubblico {get; set; }
stringa Modello pubblico {get; set; }
public string colore {get; set; }
}
Avanti, creerò un nuovo gestore classe personalizzata denominata CustomHandlerA, come si è visto in Listato 2 . Questa classe sarà anche nello spazio dei nomi CarInventory21Client del file frmMain.cs, ma al di sotto della classe frmMain. Vi spiegherò il motivo di questo più tardi.
Listing 2: La classe CustomHandlerA
Classe CustomHandlerA: DelegatingHandler
{
CustomHandlerA pubblico ()
{
}
protected override async Task <HttpResponseMessage> SendAsync (HttpRequestMessage richiesta,
CancellationToken CancellationToken)
{
// Aggiungere funzionalità personalizzate qui, prima o dopo base.SendAsync ()
WriteLog ("CustomHandlerA () - prima handler interno");
HttpResponseMessage risposta = attendere base.SendAsync (richiesta, CancellationToken);
WriteLog ("CustomHandlerA () - dopo handler interno; response.StatusCode =" +
response.StatusCode);
ritorno di risposta;
}
WriteLog public void (string msg)
{
StreamWriter sw = new StreamWriter ("C: \\ WebAPI21ClientDemo \\ LogFile.txt", true);
sw.WriteLine (DateTime.Now.ToString () + "" + Msg);
sw.Close ();
}
}
La funzionalità di questa classe è minimo e mantenuto semplice per scopi dimostrativi. Il gestore registra semplicemente un messaggio in un file di log prima e dopo la chiamata al metodo base.SendAsync. Questi messaggi vengono registrati in un file di testo utilizzando il metodo WriteLog.
Per dimostrare la sequenza di chiamate utilizzando più gestori personalizzati durante una chiamata API Web, sarò anche creare CustomHandlerB. Questa classe avrà la stessa funzionalità CustomHandlerA, ma verrà utilizzata per dimostrare la sequenza di chiamate da un gestore ad un altro.
Una volta completato, i frmMain.cs file conterrà quattro classi utilizzate in questo esempio:
frmMain: classe per Windows Forms funzionalità
Auto: modello di dati utilizzato per de-serializzare i dati ricevuti
CustomHandlerA: classe di handler HttpClient personalizzato
CustomHandlerB: classe per abitudine HttpClient gestore
Tutte le classi saranno nello spazio dei nomi CarInventory21Client. In genere, l'ordine degli oggetti all'interno di un file è irrilevante. Tuttavia, in un'applicazione Windows Form, l'errore in figura 4 viene rilevato se la classe Windows Form non è la prima classe della lista.
[Clicca sull'immagine per ingrandirla.] Figura 4. Errore Grazie al modulo di classe non essere primo nel file
L'errore si legge: "Il frmMain classe può essere progettato, ma non è la prima classe nel file di Visual Studio richiede che i progettisti utilizzano la prima classe nel file Spostare il codice della classe in modo che sia la prima classe nel file e provare.. caricare di nuovo il progettista. " Per risolvere questo errore, spostare semplicemente la classe del form alla parte superiore dello spazio dei nomi.
Guardando la classe CustomHandlerA più in dettaglio, prima che sarà ereditato da System.Net.Http.DelegatingHandler. La classe DelegatingHandler è un tipo di base per gestori HTTP, delegando l'elaborazione dei messaggi di risposta HTTP a un altro gestore, noto come il "gestore interiore." Per saperne di più su questa classe, vedere la pagina di MSDN Library, " DelegatingHandler classe . "
Una volta che la classe DelegatingHandler viene ereditata, il metodo SendAsync può essere ignorato. Questo sarà il metodo per eseguire codice personalizzato, prima o dopo la chiamata al gestore interno (base.SendAsync). Il base.SendAsync è il metodo che invia la richiesta al successivo gestore della catena.
Guardando il codice del gestore eventi per btnGet_Click nel Listato 3 , prima della firma del metodo è stato modificato per restituire in modo asincrono, utilizzando la parola chiave "async".
Listato 3: btnGetClick da frmMain.cs
privato async vuoto btnGet_Click (object sender, EventArgs e)
{
CustomHandlerA Cha = new CustomHandlerA ();
CustomHandlerB CHB = new CustomHandlerB ();
HttpClient client = HttpClientFactory.Create (CHA, CHB);
client.BaseAddress = new Uri ("http: // localhost: 15324 /");
client.DefaultRequestHeaders.Accept.Clear ();
client.DefaultRequestHeaders.Accept.Add (
nuovo MediaTypeWithQualityHeaderValue ("application / json"));
HttpResponseMessage risposta = attendere client.GetAsync ("api / auto");
se (response.IsSuccessStatusCode)
{
Auto [] = myCarArray attendono response.Content.ReadAsAsync <Auto []> ();
foreach (myCar auto in myCarArray)
{
txtResults.AppendText (string.Format ("{0} \ t {1} \ t {2} \ n \ n", myCar.Id, myCar.Make,
myCar.Model));
}
}
}
Successivamente, vengono istanziati istanze del CustomHandlerA e CustomHandlerB. Tali istanze vengono poi utilizzati durante la creazione di un oggetto HttpClient. Passando istanze dei gestori personalizzati per il metodo Create, Sono la creazione di un oggetto client con uno specifico ordine di delegare gestori. I prossimi tre istruzioni nel codice impostare URI e il tipo di formattazione JSON Media.
Dopo le proprietà richieste dell'oggetto client sono impostate, la chiamata client.GetAsync viene eseguito. Questo restituisce un oggetto HttpResponseMessage contenente i dati richiesti in formato JSON. I dati possono poi essere analizzati dall'oggetto response.Content. I risultati verranno visualizzati nella finestra dell'applicazione, come mostrato nella Figura 5 .
[Clicca sull'immagine per ingrandirla.] Figura 5. risultati visualizzati dopo aver chiamato il Web API
Guardando il contenuto del file di log (LogFile.txt), visto in qui, vedrete l'ordine di esecuzione:
2014/06/12 12:07:52 CustomHandlerA () - prima handler interno
2014/06/12 12:07:52 CustomHandlerB () - prima handler interno
2014/06/12 12:07:52 CustomHandlerB () - dopo handler interno; response.StatusCode = OK
2014/06/12 12:07:52 CustomHandlerA () - dopo handler interno; response.StatusCode = OK
venerdì 29 agosto 2014
Migrazione da Subversion a Git con svn2git su Windows (bit difficili spiegati)
Questo è uno di quei "Continuo a fare questo e mi fa male ogni volta e non c'è mai una buona risorsa concisa che spiega bene così sto scrivendo un" messaggi. Sì, sì, lo so che è facile - se si è installato Ruby. Oppure stai vivendo in un mondo * nix. O avete una ragionevole comprensione di Git. Oppure si ottiene piacere dal dolore.
Tuttavia, se stai vivendo su Windows e si desidera solo per ottenere il dannato fatto, può essere doloroso. Continuo la creazione di nuove macchine e dover ricordare come farlo da zero in modo da questo momento , sto scrivendo tutto verso il basso. Qui geos:
1) Installare Rubino
Sì, Ruby. Vai farla da Installer per Windows Rubino pagina e installare l'ultima versione con tutte le impostazioni predefinite - tranne questo:

Prendi il file eseguibile di Ruby aggiunto alla variabile d'ambiente PATH in modo che è possibile eseguire da qualsiasi punto (più sul perché presto).Avrete probabilmente bisogno di un riavvio per tale dichiarazione PATH a calci in troppo.
Perché Ruby? Perché svn2git è scritto su di esso in modo che non stai andando lontano fino ad avere questo correre.
2) Installare la gemma svn2git
Se gemme sono un concetto estraneo, sono i pacchetti NuGet del mondo di Ruby. È possibile prendere la gemma svn2git direttamente dalla riga di comando, basta accendere una finestra di comando ed eseguire questo (il percorso si esegue da non importa se hai aggiunto la dichiarazione PATH per il passaggio precedente):
gem install svn2git
Poi attendere che la magia accada:

Questo è svn2git ora installato. Nel caso foste curiosi, la gemma finisce diffusione fuori attraverso il vostro percorso di installazione di Ruby:

3) Migrare il repository Subversion
E, naturalmente, ciò che tutti noi venuti qui per, in primo luogo - di pompaggio che repository Subversion in Git. Fare riferimento alla pagina del progetto su GitHub svn2git per l'utilizzo o dargli un po 'di "svn2git -h", mentre nella finestra di comando sul sentiero sopra. A seconda della configurazione, è possibile trovare è necessario fornire esplicitamente le credenziali quando si esegue questo comando in modo da considerare che.In breve, però, stiamo andando a puntare lo strumento ad una distanza repository Subversion e ottenere per creare un locale repository Git.
Per l'amor di esempio, ho intenzione di eseguire questo in una nuova cartella locale ho creato in c: \ MyProject:
http svn2git: // [nome del dominio] / svn / [root repository]
Dopo che tutte le corse, avrete un repository Git completo con tutto il codice e la cronologia delle revisioni nella cartella c: \ MyProject percorso.Vai avanti e utilizzare il vostro client preferito Git e controllare la cronologia commit - sembra familiare? Dovrebbe.
Un Gotcha qui e per il bene di Googleability, ripeto l'errore si può vedere:
Comando non riuscito: git checkout -f maestro
Questo è ciò che accade quando si punta svn2git in un percorso sotto la radice del repository, come "tronco". E 'facile da fare in quanto è probabilmente il tronco si è verificato a livello locale e, se farete ciò che io faccio e ricevo intorno copiare e incollare link, è molto facile fare questo e mi chiedo cosa sta succedendo. Controlla il tuo percorso!
4) Spingere il repository da qualche parte utile (come GitHub)
Giusto per chiudere il ciclo del flusso di lavoro che molte persone passare attraverso, sarete spesso finiscono per voler prendere il vostro nuovo repository lucido e colpire fino a qualche parte come GitHub. Ho un repository demo vuoto che sembra proprio come questo:

Vado a prendere l'URL del repository (è laggiù verso il basso a destra nell'immagine sopra) e aggiungerlo come un remoto :
git add remota origine https://github.com/troyhunt/MyProject.git
Proprio come un controllo di integrità, darò un po 'di "-v remoto git" per confermare che è completato con successo:

Ora cerchiamo di spingere tutti i rami locali fino a GitHub
git push -all
Il che ci dà:

E abbiamo finito! Facciamo sanità mentale controllare che su GitHub:

32 commit - c'è la vostra storia!
Incartare
Questa è una visione volutamente semplicistica che intenzionalmente non tocca su una serie di varie questioni, ma è tutto su come ottenere installato e funzionante come facilmente possibile.
Iscriviti a:
Post (Atom)